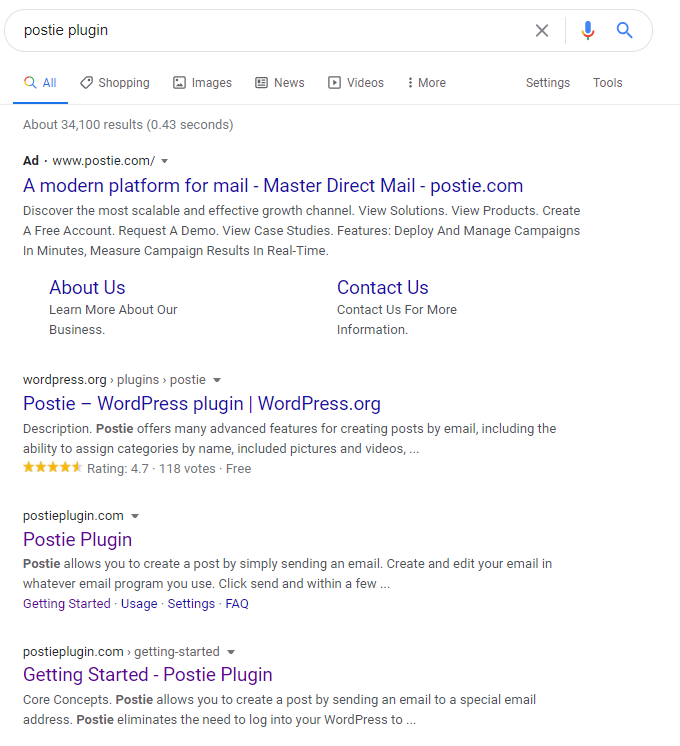
Some time ago I was looking for ways to send in posts to my WordPress blog via email, and I found a reference to a WordPress plugin called “Postie.” So I popped that into Google search and what did I get?
The correct answer to this search would be the Postie WordPress plugin hosted here. But apparently there is another company named Postie which manages enterprise mail (hosted at postie.com) which is a completely separate entity to the WordPress plugin (hosted at postieplugin.com). As you can see from the screenshot, my search resulted in an ad for the enterprise company.
But I have no interest in enterprise mail. That ad is effectively wasted. Worse yet, the CTR (clickthrough rate, the number of times the ad is clicked on divided by the number of times the ad is shown) of the ad goes down through no fault of the ad itself. But you can see why the ad was shown – the ad’s creator placed ads on the word “postie” and didn’t realize there might be other organizations with the same name.
This is a good example of where negative keywords are used. In short negative keywords are used to find searches to NOT show ads to. In this case, Postie (the enterprise company) should have used negative keywords to exclude the word “plugin” so they’re not confused with Postie Plugin (the WordPress plugin).
If you’re interested in search optimization, you’ll know about Google’s new search update that released in March 2024. Per Google, the search update is intended to weed out low effort sites, sites with a ton of AI content, affiliate review sites, and so forth. A good outline of what went on in this update is here.
In short, a lot of chaos occurred. Major publications are reporting pretty severe drops in traffic; smaller sites are reporting traffic drops of greater than 90%. Here’s a fun quote:
BBC News, for example, was among the sites that saw the biggest percentage drops, with its site losing 37% of its search visibility having fallen from 24.7 to 15.4 points in a little over six weeks. Its relative decline was second only to Canada-based entertainment site, Screenrant which saw its visibility fall by 40% from 27.6 to 16.7.
There’s a lot of doom and gloom about this update, but I’m really liking it. I’m seeing a lot of very interesting stuff float up on my Google searches that normally would be buried. In particular I’m seeing fewer “top 10 XYZ” type webpages and more links to opinion websites such as Reddit and other forums.
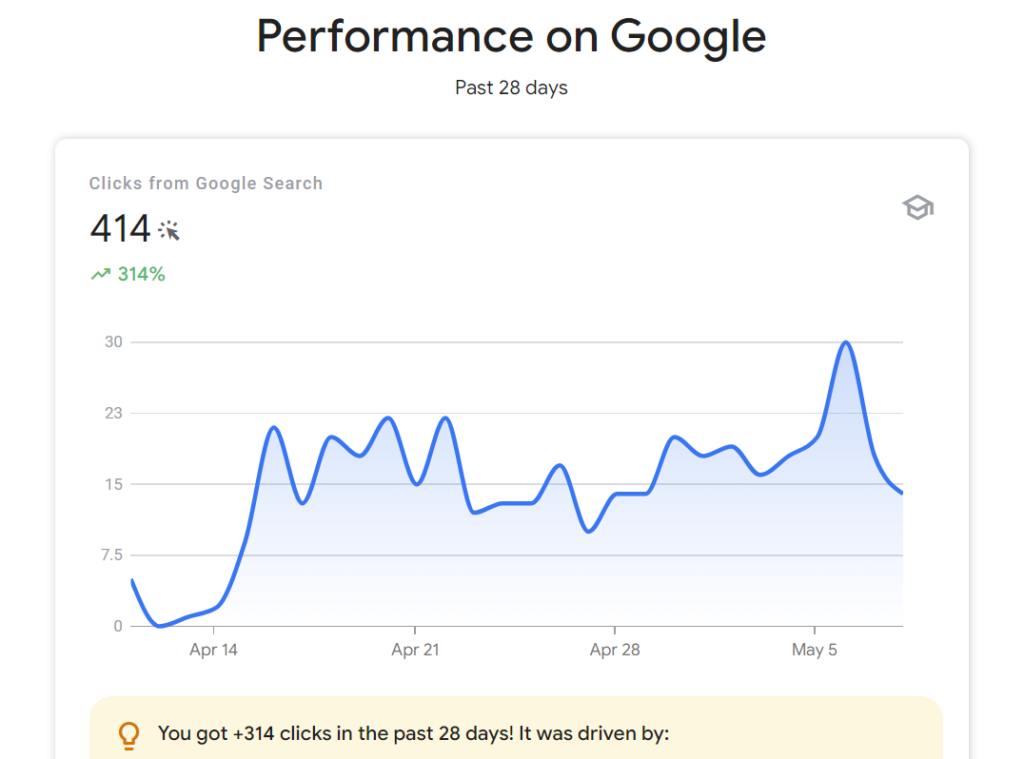
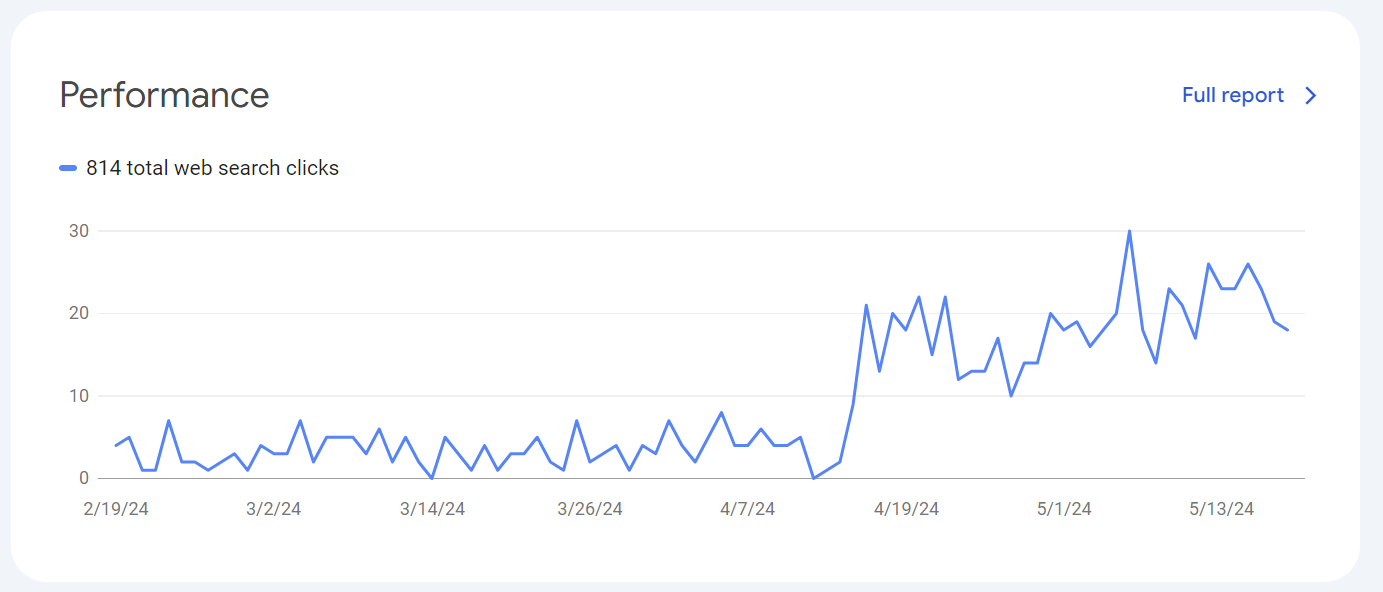
And then there’s this: one of my websites is reporting 314% more clicks from Google search.
I run a small blog (not this one) which is basically a tumblelog-style fan blog for a specific consumer-goods company. It really doesn’t do much except repost funny pictures and interesting articles. The blog typically gets about 100 clicks a month from Google search – which never ceases to amaze me, especially since the site itself is so simple.
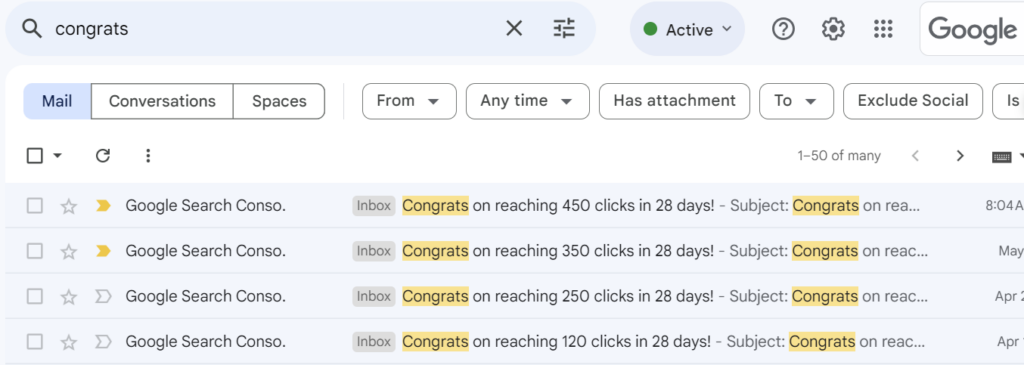
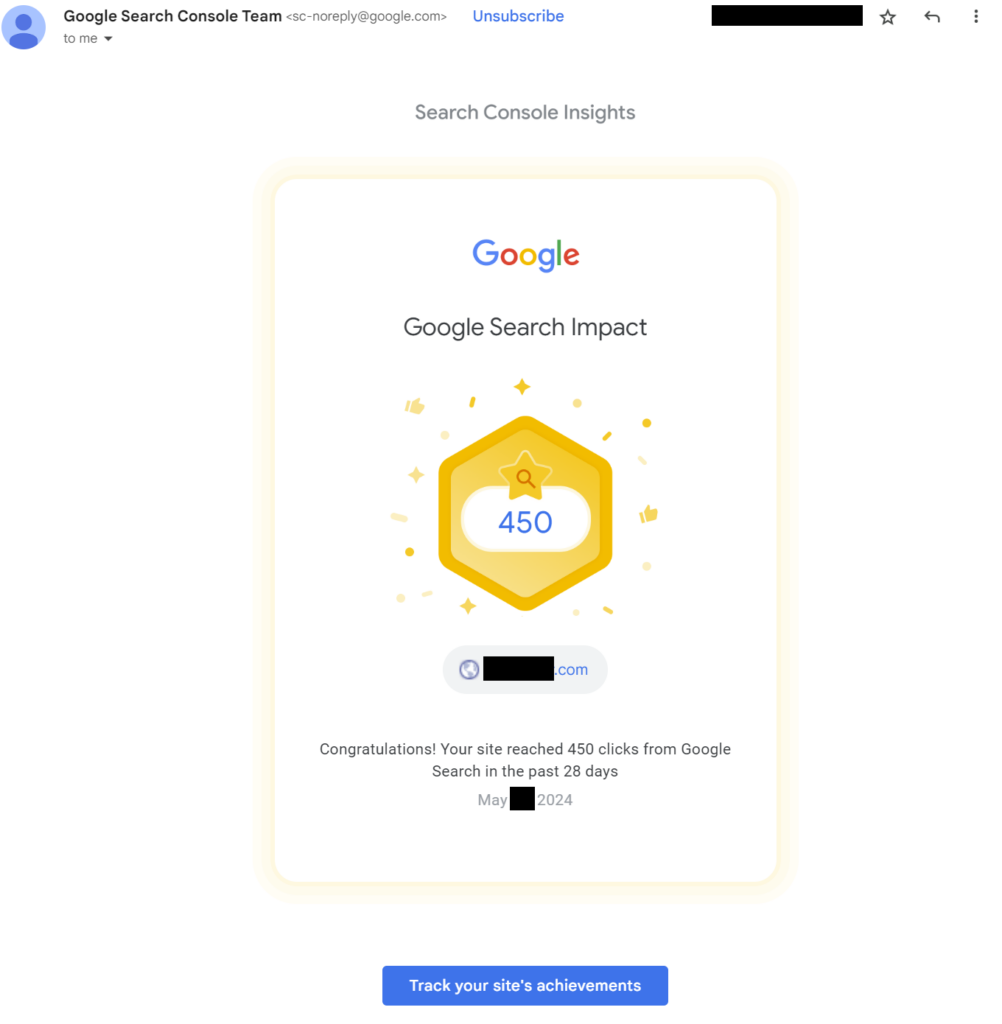
With that in mind, I was shocked to suddenly see a burst of emails over the past month congratulating me over a sudden rise in traffic:
A sample of the emails:
What on earth is going on? A quick view of my search console shows the truth:
I’m not making any larger point here, it’s just interesting to see how fast things can change during a search core update.
I always love pointing out fun errors – where I define “fun error” as an error that is intermittent/happens rarely in the context of regular operation in the application. Those errors are always the most fun to fix.
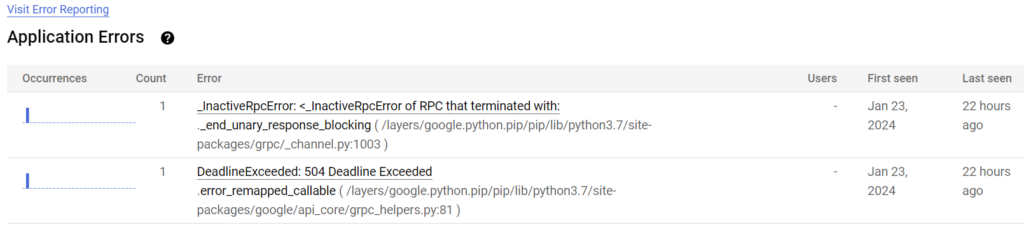
Today I was poking through some of my toy applications running on Google Cloud when I saw this:
And the text only:
_InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
._end_unary_response_blocking ( /layers/google.python.pip/pip/lib/python3.7/site-packages/grpc/_channel.py:1003 ) - Jan 23, 2024 22 hours ago -
DeadlineExceeded: 504 Deadline Exceeded
.error_remapped_callable ( /layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/grpc_helpers.py:81 ) - Jan 23, 2024 22 hours ago
Hmm – so an error occurred 22 hours ago, that last reoccurred almost 4 months ago (Jan 23, 2024). Doesn’t sound very important. But just for the laughs, let’s dig in.
Of the two errors, I know that the first one (InactiveRPCError) is most likely due to a connection being unable to complete. Not a giant problem, happens all the time in the cloud – servers get rebooted, VMs get shuffled off to another machine, etc. Not a serious problem. The deadline exceeded one concerns me though because I know this application connects to a bunch of different APIs and does a ton of time consuming operations, and I want to make sure that everything is back to normal.
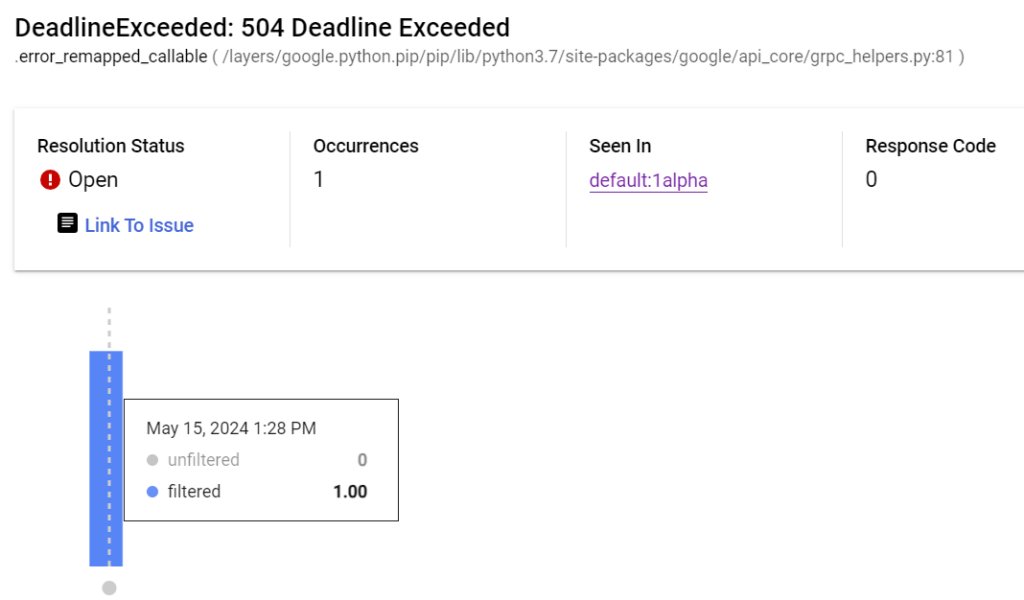
So here’s the view of the error page:
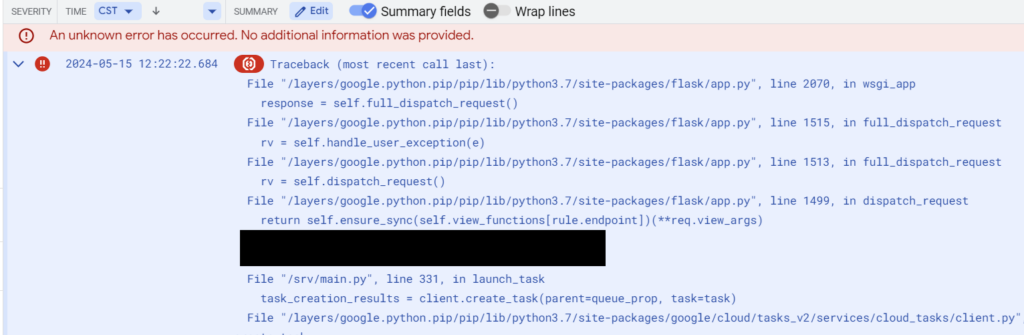
So I know that the error is somewhere communicating with Google services since the error pops up in the google api core library. Let’s hop on over to logging and find the stack trace – I’ve redacted a line that doesn’t mean anything to the purpose of this post:
Traceback (most recent call last):
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 2070, in wsgi_app
response = self.full_dispatch_request()
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1515, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1513, in full_dispatch_request
rv = self.dispatch_request()
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1499, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args)
[REDACTED]
File "/srv/main.py", line 331, in launch_task
task_creation_results = client.create_task(parent=queue_prop, task=task)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/cloud/tasks_v2/services/cloud_tasks/client.py", line 2203, in create_task
metadata=metadata,
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/gapic_v1/method.py", line 131, in __call__
return wrapped_func(*args, **kwargs)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/timeout.py", line 120, in func_with_timeout
return func(*args, **kwargs)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/grpc_helpers.py", line 81, in error_remapped_callable
raise exceptions.from_grpc_error(exc) from exc
google.api_core.exceptions.DeadlineExceeded: 504 Deadline Exceeded
If you missed the culprit in the above text, let me help you out: the call to the Google Task Queue service on line 331 of my application ended up exceeding Google’s deadline, and threw up the exception from Google’s end. Perhaps there was a transient infrastructure issue, perhaps task queue was under maintenance, perhaps it was just bad luck.
File "/srv/main.py", line 331, in launch_task
task_creation_results = client.create_task(parent=queue_prop, task=task)
There’s really nothing to be done here, other than maybe catching the exception and trying again. I will point out that the task queue service is surprisingly resilient: out of tens/hundreds of thousands of task queue calls over the past 5 months that this application has performed, only 2 tasks (one in January 2024, one yesterday) have failed to enqueue. More importantly, my code is functioning as intended and I can mark this issue as Resolved or at least Muted.
Now honestly, this is a my bad sort of situation. If this was a real production app there should be something catching the exception. But since this is a toy application, I absolutely am fine tolerating the random and thankfully very rare failures in task queue.
I was working on some fun LeetCode type questions, and I came across a challenge to replicate the Vigenere cipher encryption and decryption in Python.
In short, the Vigenere cipher allows one to encrypt and decrypt a message if the user knows an alphabetic key. It’s notable for being easy to use; encryption and decryption are done by overlaying the key next to the message, then shifting the message letter by the letter number of the overlaid key. For more information, see the Wikipedia page discussing the Vigenere cipher .
The below functions are the “know-your-number-theory” / expected versions of how to encrypt/decrypt, where c is the encrypted message to decrypt, m is the unencrypted text to encrypt, and keyword is the secret encoding key.
def vigenere_decrypt_cipher(c: str, keyword: str) -> str:
keyword_repeated = (keyword * (len(c) // len(keyword))) + keyword[:len(c) % len(keyword)]
plaintext = ''
for i in range(len(c)):
if c[i].isalpha():
shift = ord(keyword_repeated[i].upper()) - ord('A')
if c[i].islower():
plaintext += chr((ord(c[i]) - ord('a') - shift) % 26 + ord('a'))
else:
plaintext += chr((ord(c[i]) - ord('A') - shift) % 26 + ord('A'))
else:
plaintext += c[i]
return plaintext
def vigenere_encrypt_message(m: str, keyword: str) -> str:
#filter to kick out spaces and punctuation
filtered_m = ""
for toon in m:
if toon.isalpha():
filtered_m = filtered_m + toon
else:
pass
#the rest to process the "real" stuff
m = filtered_m.upper()
keyword = keyword.upper()
encrypted_message = ''
keyword_repeated = (keyword * (len(m) // len(keyword))) + keyword[:len(m) % len(keyword)]
for i in range(len(m)):
char = m[i]
if char.isalpha():
shift = ord(keyword_repeated[i].upper()) - ord('A')
if char.islower():
encrypted_message += chr((ord(char) - ord('a') + shift) % 26 + ord('a'))
else:
encrypted_message += chr((ord(char) - ord('A') + shift) % 26 + ord('A'))
else:
encrypted_message += char
return encrypted_message.upper()
Honestly, while it was fun to implement, it’s not immediately obvious how Vigenere’s works from the code. So for fun I wrote the functions below, which sort of mimics how Vigenere messages would be coded/decoded by hand:
While these functions are much longer, I think they’re much more readable than the previous set of functions. These versions generate a matrix of 26×26 alphabets; the first row is a to z, the second row is shifted 1 to the right (b to z then a), the third row is shifted 2 to the right (c to z then ab), etc. Then we overlay the secret key and use it along with the message/encrypted message to encrypt/decrypt by finding the appropriate entry in our matrix. Admittedly the code is a little ugly and could be cleaned up, but I thought it would be fun to share.
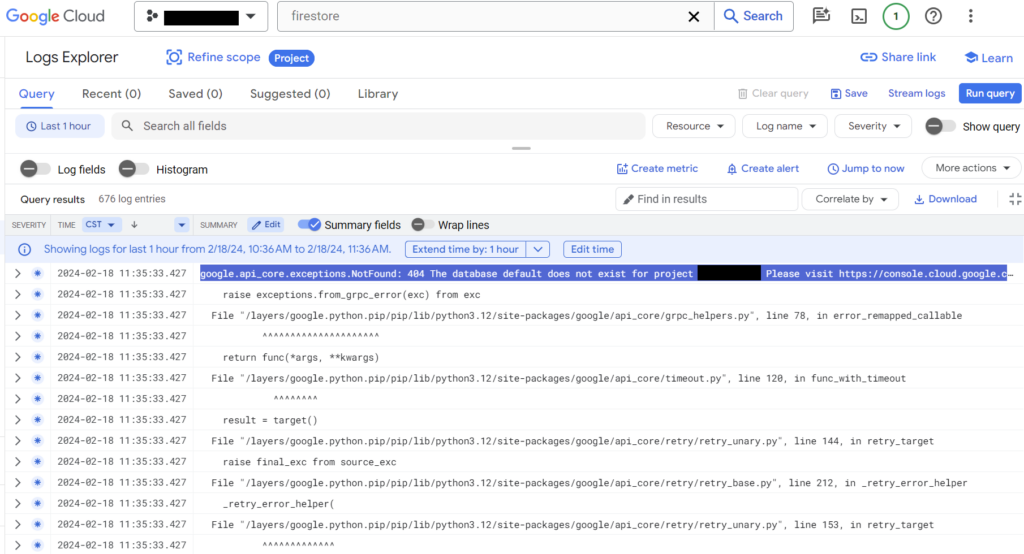
I opened up a new Google Cloud project to act as a staging project and forgot to set up a Firestore database for the project, and got the following error:
google.api_core.exceptions.NotFound: 404 The database default does not exist for project magicalnews Please visit https://console.cloud.google.com/datastore/setup?project=[projectname] to add a Cloud Datastore or Cloud Firestore database
Google Cloud Logging
Obviously to fix this you need to create a Cloud Firestore or Cloud Datastore, but I will say I love the detailed error message and the direct link to fix the problem. I’m noticing a lot of small developer experience fixes and filing down of “sharp edges” – I hope they continue because the developer experience on Google Cloud is just getting better and better.
Here’s some quick code samples for shifting a UTC datetime object (created_at is a datetime.utcnow()) to a different timezone. In this first example, we use timedelta to add/remove hours to find the current time at UTC-6:00.
But my favorite example of Internet marketing over Christmas is NORAD Tracks Santa, located at https://www.noradsanta.org/. NORAD stands for North American Aerospace Defense Command – it’s a joint military command between American and Canadian militaries to protect the skies over both countries. Every year, the website above tracks Santa as he goes around the world delivering presents.
Now you may say: wait a minute, NORAD isn’t selling a product or service, this isn’t an example of marketing. Marketing is far more than just selling a product or service; it also includes burnishing a brand, or building greater awareness of an organization. In this case, I’m using marketing in the context of how NORAD uses NORAD Tracks Santa to build greater public awareness of its mission, and to burnish its reputation. That last part – burnishing reputation – can be helpful for government agencies, especially when asking for funding from Congress.
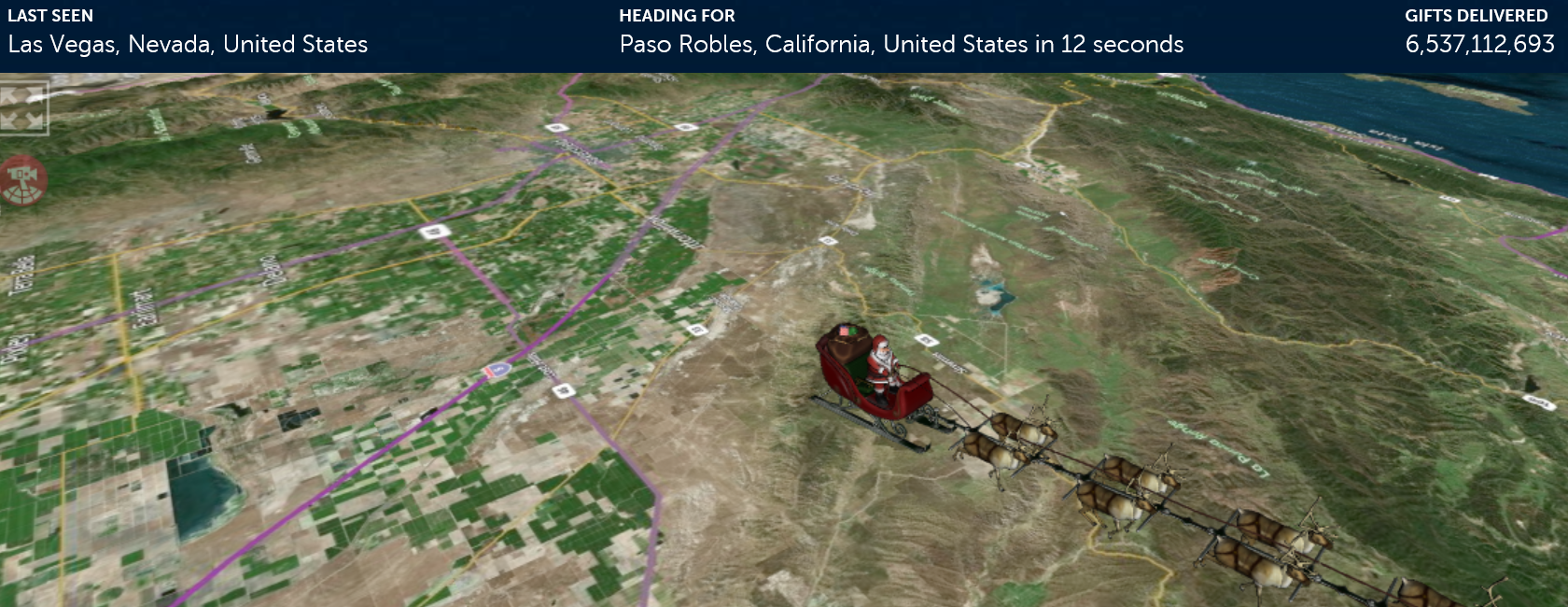
The NORAD Tracks Santa website is really neat – if you look at it Christmas Eve night, you see an animation of Santa flying over a world map (the world map is provided by Microsoft Bing). Here’s an example screenshot:
A screenshot of the NORAD Tracks Santa page on Christmas Eve.
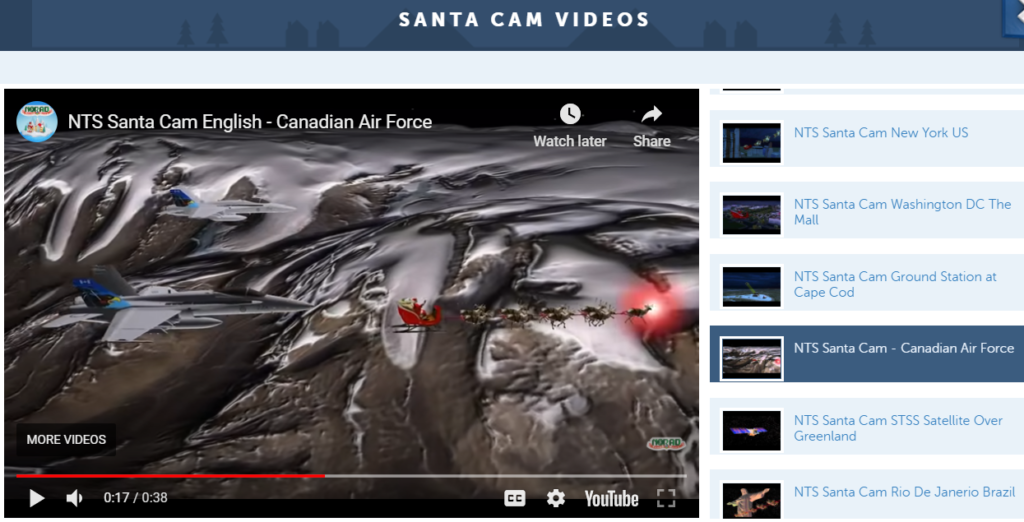
The reason I love NORAD Tracks Santa as a great example of Internet marketing is how it seamlessly blends marketing, education, and the holidays in one package. For instance, look at this video from the NORAD Tracks Santa page:
A screenshot from one of the Santa-tracking videos on NORAD Tracks Santa. The video embedded on the page is hosted by YouTube. Click on the picture to go to the full video.
The YouTube video embedded on the page goes to here: https://www.youtube.com/watch?v=pR-_novdArc – go ahead and watch it. Pay close attention to what it says and more importantly, what it does not say.
Here’s a transcript of the video’s narrator if you can’t watch the video:
NORAD is receiving reports that Santa’s sleigh is moving north toward Canadian airspace from the Mid-Atlantic. CF-18 Hornets from the Royal Canadian Air Force are escorting Santa through Canadian airspace. As part of Operation Noble Eagle – NORAD’s mission to safeguard North American skies – CF-18s maintain a constant state of alert, ready to respond immediately to potential threats to the homelands. Santa and his reindeer certainly pose no threat but he can rest easy knowing that the NORAD team has the watch ensuring safe travels across North America.
NORAD Tracks Santa, NTS Santa CAM – Canadian Air Force
Consider how well the marketing is done here. There’s a education element at play (explaining Operation Noble Eagle), a marketing element (associating NORAD with the holidays, which is a positive association) and the entertainment element of watching Santa be escorted by fighter jets.
But also consider what is not said in the video and merely implied. The viewer sees the fighter jets smoothly move into an escort position, implying experience and professionalism in regards to the fighter pilots and the NORAD organization as a whole. The viewer sees the fighters soar across mountainous and ice-covered lands, implying the hard and difficult job of the organization.
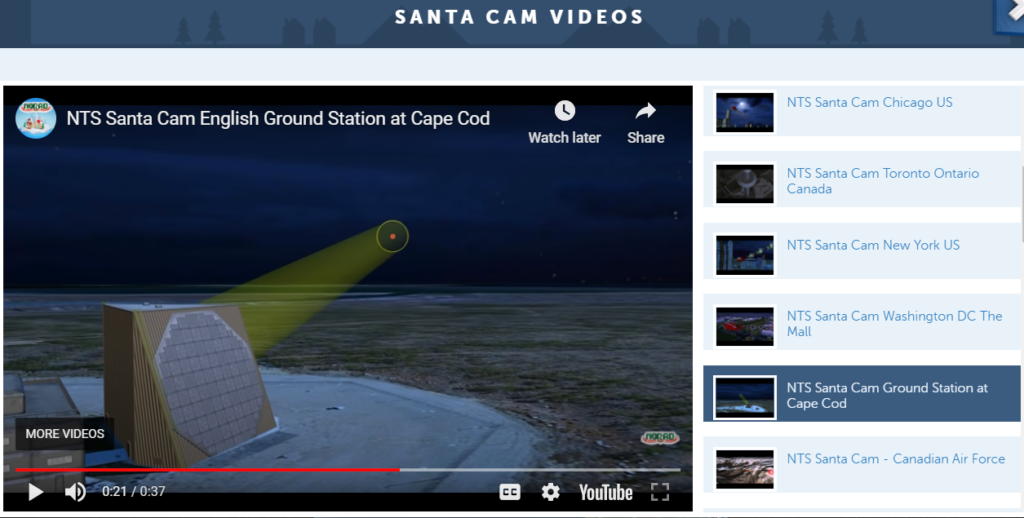
Let’s try another example – here is a video of NORAD tracking Santa through Massachusetts:
A screenshot of NORAD Tracks Santa. The video is embedded from YouTube and covers how NORAD tracks Santa through the Massachusetts area. Click the picture to see the full video on YouTube. The red dot at the center of the yellow beam is not a tracking target; it’s Rudolph the Reindeer’s lighted red nose.
The above screenshot embeds the following video, which tracks Santa as he passes over the Cape Cod Air Force Station: https://www.youtube.com/watch?v=RGchQuqqwd4 . I recommend watching it, but here’s a transcript if you can’t:
NORAD was notified by Air Force Space Command that their PAVE phased-array warning system – early warning radar known as PAVE PAWS at Cape Cod Air Force Station Massachusetts – is tracking Santa on his way from the US to South America. This radar is not only capable of detecting ballistic missile attacks and conducting general Space Surveillance and satellite tracking, but at this time of year the PAVE PAWS station keeps an eye on Santa as he flies over the Atlantic toward the Western Hemisphere.
NTS Santa Cam English Ground Station at Cape Cod
Again, note the educational aspects of the video (what PAVE PAWS stands for and what it does), the marketing aspects of the video (associating NORAD and the Air Force with the holiday season) and the entertainment element of watching Santa.
But again consider what is not said. The video implies professionalism (someone is manning the station at night on a holiday) and security (someone is on the watch for possible threats).
The Takeaway
NORAD Tracks Santa is a masterpiece of marketing done right. Consider adding similar elements to your online marketing strategy, such as a simple game, amusing videos, and educational content discussing your organization’s mission.
I’ve been experimenting with filtering and manipulating a large amount of data within a Google Cloud Function. I decided to use an in-memory SQLite database to help manage all the data, so I googled up some code samples. This page came up with some helpful Python code samples.
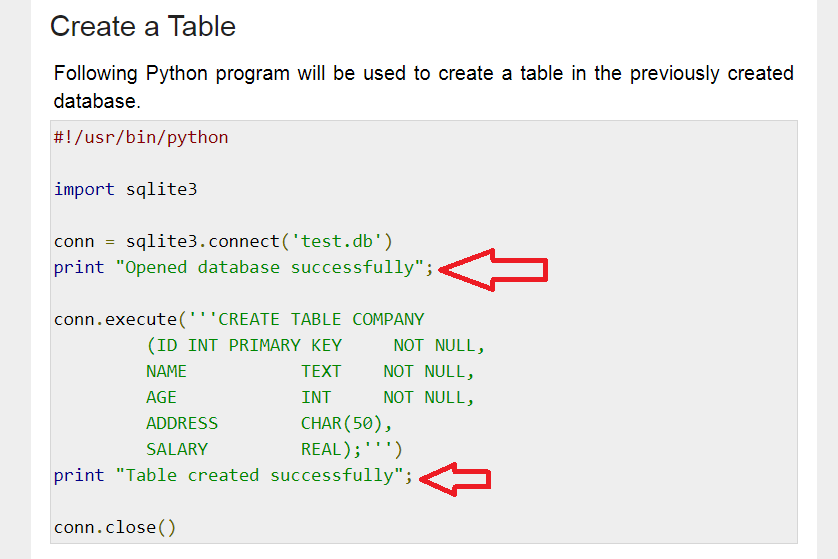
Unfortunately when I tried to run the sample code, Cloud Functions popped an error. The sample code uses Python 2-style print as a statement instead of as a function call – i.e. the print call is missing the parentheses needed to make it a correct function call. Here’s a sample screenshot:
I’ve placed red arrows next to the erroneous print statements. If you paste this code into Google Cloud Functions, it won’t work because print needs to be a function call, (with parentheses) instead of a statement (missing parentheses). Credit: https://www.tutorialspoint.com/sqlite/sqlite_python.htm
Below is a fixed version of the code in the linked page. You can paste it directly into the Google Cloud Functions editor and it’ll work: it sets up an in-memory database, creates a table, adds data, then queries data out of it.
import sqlite3
def hello_world(request):
"""Responds to any HTTP request.
Args:
request (flask.Request): HTTP request object.
Returns:
The response text or any set of values that can be turned into a
Response object using
`make_response <http://flask.pocoo.org/docs/1.0/api/#flask.Flask.make_response>`.
"""
conn = sqlite3.connect(":memory:")
conn.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print("Records created successfully");
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print("ID = ", row[0])
print("NAME = ", row[1])
print("ADDRESS = ", row[2])
print("SALARY = ", row[3], "\n")
conn.close()
request_json = request.get_json()
if request.args and 'message' in request.args:
return request.args.get('message')
elif request_json and 'message' in request_json:
return request_json['message']
else:
return f'Hello World!'
Use this code as a starting point to build your own cloud functions and work with data.
I’m pleasantly surprised at how fast SQLite runs within a cloud function – I was worried that the function would run out of memory quickly, but I’ve been manipulating thousands of rows comfortably within a 512MB RAM function.
I have a demo App Engine application on GitHub, mapped through Google Cloud Build to automatically redeploy upon any change in the master repository. I’ve left this app untouched for about a month or so, until now where I made some minor updates and pushed those updates to the GitHub repository.
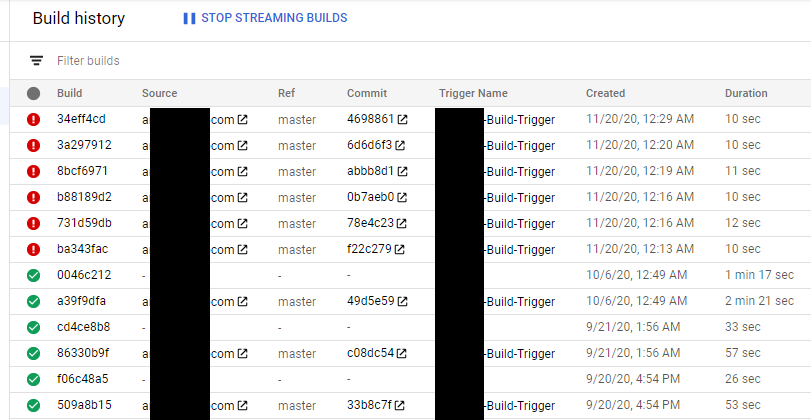
Unfortunately it seems that Cloud Build has changed some permissions, because suddenly errors came up and my updates failed to deploy. Here’s a screenshot of my Cloud Build page, and the errors:
My Cloud Build page. All my builds in October and earlier of this year succeeded, but my November builds started failing.
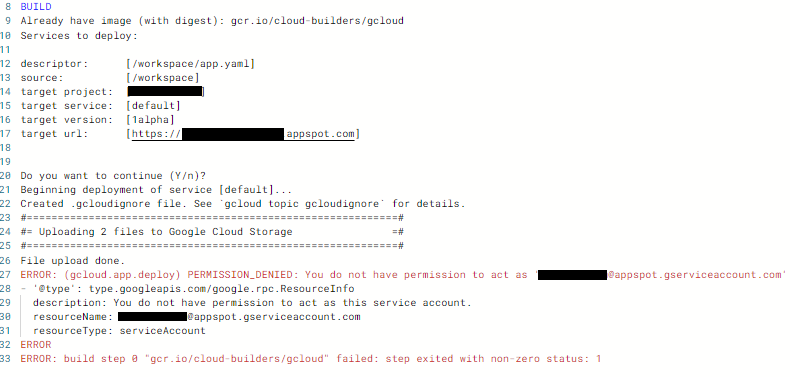
Apparently this error was due to a permissions error
ERROR: (gcloud.app.deploy) PERMISSION_DENIED: You do not have permission to act as '[email protected]'
- '@type': type.googleapis.com/google.rpc.ResourceInfo
description: You do not have permission to act as this service account.
resourceName: [email protected]
resourceType: serviceAccount
ERROR
ERROR: build step 0 "gcr.io/cloud-builders/gcloud" failed: step exited with non-zero status: 1
Error detail in context.
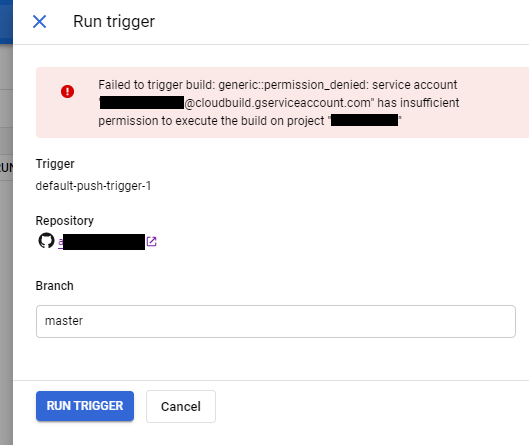
When I tried to force the run via the Run trigger, I got this error:
Failed to trigger build: generic::permission_denied: service account [email protected] has insufficient permission to execute the build on project project-name.
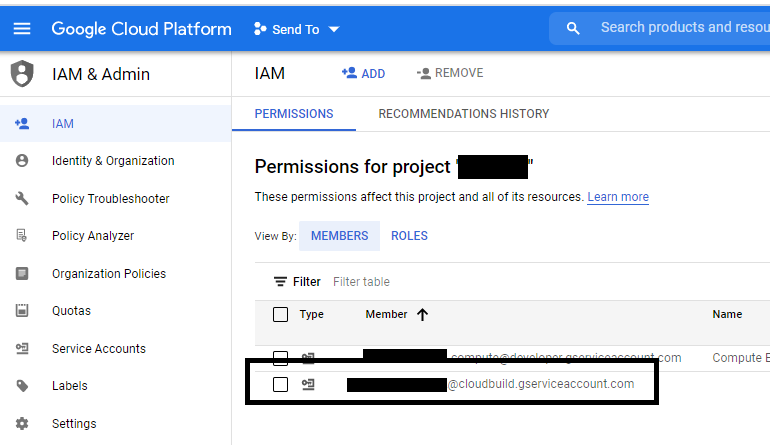
In short, you need to add the Cloud Build Service Agent role to Cloud Build, allowing it to use service accounts to authenticate into other Google services. in the IAM section of the cloud console, find the Cloud Build service account:
The Cloud Build service account is in the black box.
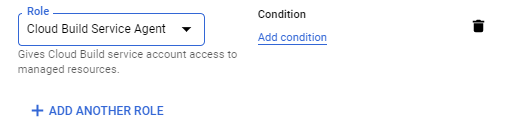
And then add the Cloud Build Service Agent to the Cloud Build service account:
After I added that role, my Cloud Build deployments worked again.
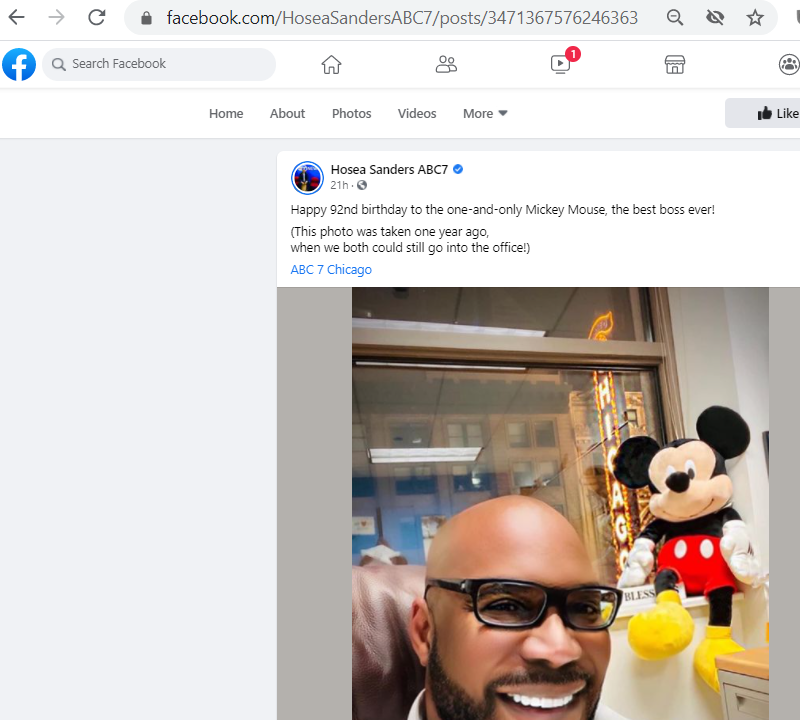
Yesterday, November 18 2020, was Mickey Mouse’s 92nd birthday. You may have seen it on your local news; I saw it mentioned on my local ABC station (ABC is owned by Disney).
Here’s a screenshot of a news-anchor from my local ABC affiliate commenting on Mickey’s birthday:
Extracted from https://www.facebook.com/HoseaSandersABC7/posts/3471367576246363
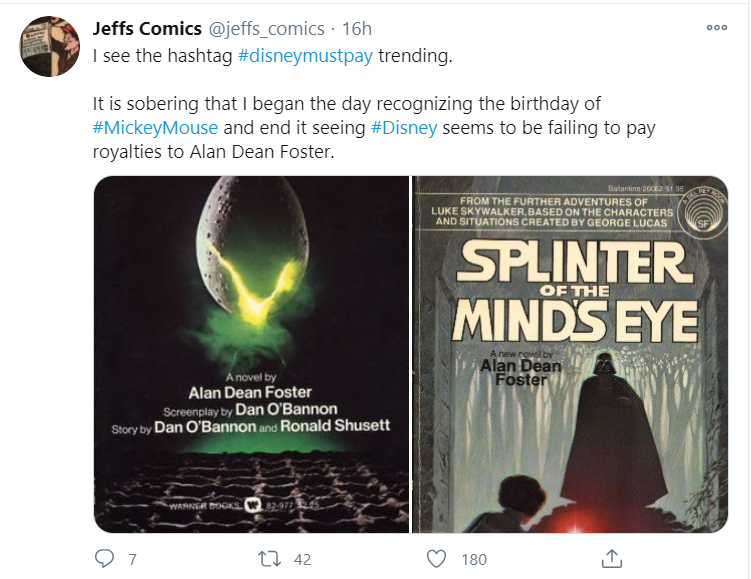
Unfortunately for Disney, Mickey’s 92nd birthday was not a major topic of conversation on Twitter and other social media locations. You may have seen another story about Disney bubble up yesterday, and this story is much less flattering to Disney: SFWA – #DisneyMustPay Alan Dean Foster. In short, Disney is accused of not paying royalties to Alan Dean Foster, who wrote a number of Star Wars and Aliens novels that Disney acquired the rights to when it purchased LucasFilm and Fox.
This story (and the hashtag #disneymustpay) was a trending item on Twitter for most of yesterday; this tweet summarizes the situation very well:
Extracted from https://twitter.com/jeffs_comics/status/1329214047569448962
I’m not here to litigate which side is correct, but I did want to point out the beauty of how this story was marketed: it was set up as counterprogramming against the story of Mickey Mouse’s 92nd birthday.
Yesterday’s news started with Mickey Mouse’s 92nd birthday on the news cycle: that “primed the pump” for more Disney related stories. By publishing the article #DisneyMustPay Alan Dean Foster on the same day, the article received much bigger growth and coverage than it would have if published on any other day. It inflicted reputational damage on Disney (which hurts more because Disney is a consumer-focused company) and cost Disney the chance to use Mickey’s 92nd birthday to drive more sales (because on November 18th consumers were thinking of Alan’s story, not Mickey Mouse). All in all, the SFWA managed to get Disney’s attention in a big way, and I’m sure Alan’s story is now being considered in the executive level of Disney’s management.
This case is a great example for any guerilla marketing campaigns: set up your marketing as counterprogramming to a bigger rival’s work; you’ll get far more reach out of your campaigns and your rival’s marketing will be much less successful.