From the “my blog is actually my code backup store” department, this is a simple function I use on Google Cloud to accept a base64-encoded zip file, then unzip it all to a Google Cloud Storage bucket.
import functions_framework
import base64
from google.cloud import storage
import zipfile
import os
import datetime, pytz
@functions_framework.http
def hello_http(request):
#pull out the base64 encoded data and decode it.
request_bytes = base64.b64decode(request.get_data())
print(len(request_bytes))
print(request.data)
print(request.content_length)
print(request.method)
print(request.method)
print("request load: " + str(len(request_bytes)))
#generate working directory prefix name
datetime_string = datetime.datetime.now(pytz.timezone("US/Central")).isoformat()
print("Current Chicago Date-Time: %s" % (datetime_string))
directory_prefix = datetime_string[:19].replace(":", "-")
#dump to GCS
gcs_client = storage.Client()
gcs_bucket = gcs_client.get_bucket("bucket name goes here")
file_blob = storage.Blob("/zipped/" + directory_prefix + ".zip", gcs_bucket)
file_blob.upload_from_string(request_bytes, content_type="application/zip", client=gcs_client)
#dump to temporary directory within functions
with open("/tmp/" + directory_prefix + ".zip", "wb") as file:
file.write(request_bytes)
file.flush()
file.close()
#extract zipfile
zip_file = zipfile.ZipFile("/tmp/" + directory_prefix + ".zip")
zip_file.extractall("/tmp/local/unzip/" + directory_prefix + "/")
#go through extracted files
for file_name in os.listdir("/tmp/local/unzip/" + directory_prefix + "/"):
print(str(file_name))
file_blob = storage.Blob("/open/" + directory_prefix + "/" + file_name + "", gcs_bucket)
file_blob.upload_from_filename("/tmp/local/unzip/" + directory_prefix + "/" + file_name + "", client=gcs_client)
print("end")
return str(len(request_bytes))
You may want to alter the date reference (the US/Central note) but otherwise it’s a small and efficient tool for moving data where I can easily reference it later by date.
I always love pointing out fun errors – where I define “fun error” as an error that is intermittent/happens rarely in the context of regular operation in the application. Those errors are always the most fun to fix.
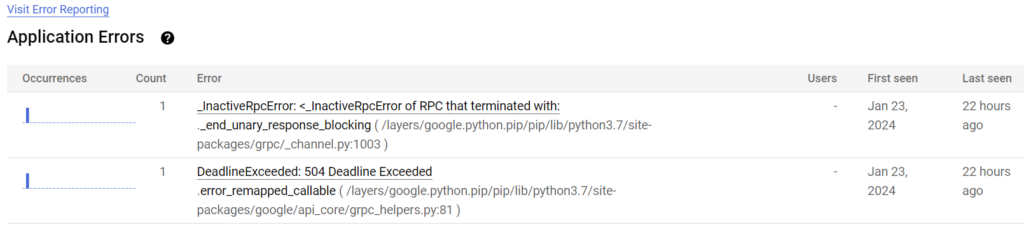
Today I was poking through some of my toy applications running on Google Cloud when I saw this:
And the text only:
_InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
._end_unary_response_blocking ( /layers/google.python.pip/pip/lib/python3.7/site-packages/grpc/_channel.py:1003 ) - Jan 23, 2024 22 hours ago -
DeadlineExceeded: 504 Deadline Exceeded
.error_remapped_callable ( /layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/grpc_helpers.py:81 ) - Jan 23, 2024 22 hours ago
Hmm – so an error occurred 22 hours ago, that last reoccurred almost 4 months ago (Jan 23, 2024). Doesn’t sound very important. But just for the laughs, let’s dig in.
Of the two errors, I know that the first one (InactiveRPCError) is most likely due to a connection being unable to complete. Not a giant problem, happens all the time in the cloud – servers get rebooted, VMs get shuffled off to another machine, etc. Not a serious problem. The deadline exceeded one concerns me though because I know this application connects to a bunch of different APIs and does a ton of time consuming operations, and I want to make sure that everything is back to normal.
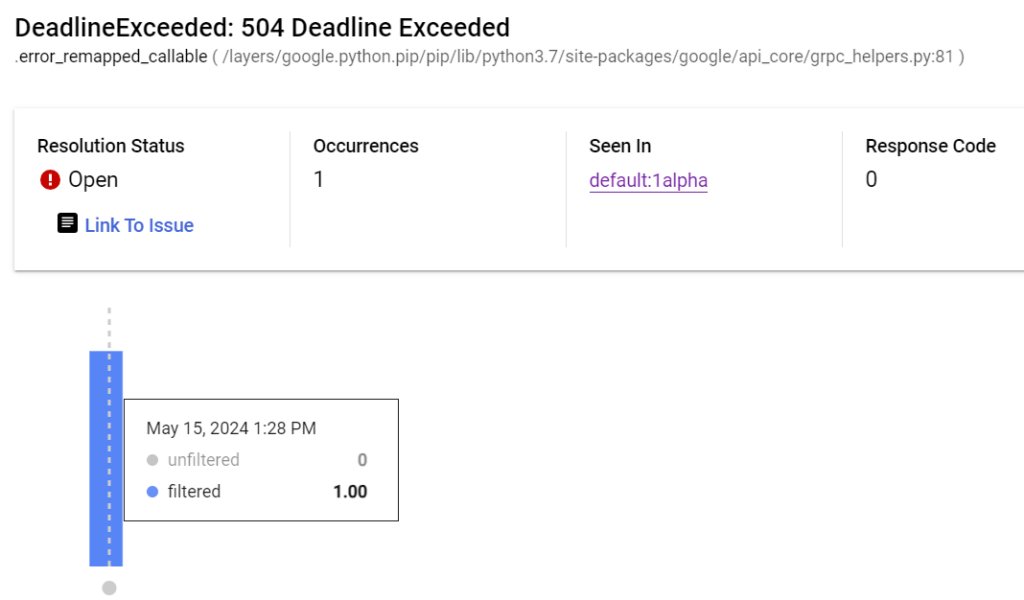
So here’s the view of the error page:
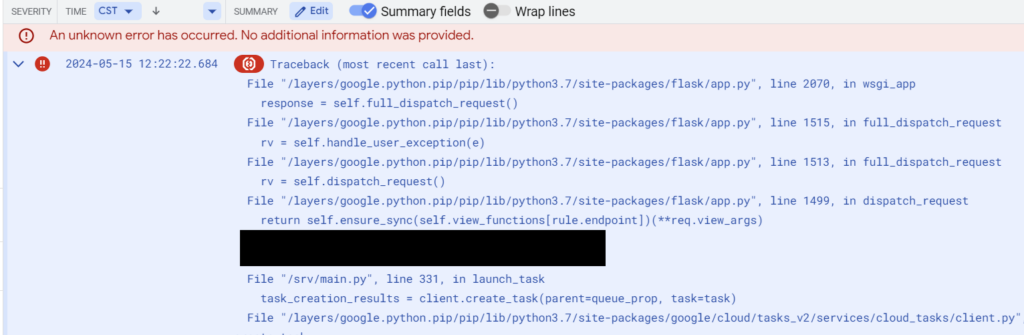
So I know that the error is somewhere communicating with Google services since the error pops up in the google api core library. Let’s hop on over to logging and find the stack trace – I’ve redacted a line that doesn’t mean anything to the purpose of this post:
Traceback (most recent call last):
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 2070, in wsgi_app
response = self.full_dispatch_request()
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1515, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1513, in full_dispatch_request
rv = self.dispatch_request()
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1499, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args)
[REDACTED]
File "/srv/main.py", line 331, in launch_task
task_creation_results = client.create_task(parent=queue_prop, task=task)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/cloud/tasks_v2/services/cloud_tasks/client.py", line 2203, in create_task
metadata=metadata,
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/gapic_v1/method.py", line 131, in __call__
return wrapped_func(*args, **kwargs)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/timeout.py", line 120, in func_with_timeout
return func(*args, **kwargs)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/grpc_helpers.py", line 81, in error_remapped_callable
raise exceptions.from_grpc_error(exc) from exc
google.api_core.exceptions.DeadlineExceeded: 504 Deadline Exceeded
If you missed the culprit in the above text, let me help you out: the call to the Google Task Queue service on line 331 of my application ended up exceeding Google’s deadline, and threw up the exception from Google’s end. Perhaps there was a transient infrastructure issue, perhaps task queue was under maintenance, perhaps it was just bad luck.
File "/srv/main.py", line 331, in launch_task
task_creation_results = client.create_task(parent=queue_prop, task=task)
There’s really nothing to be done here, other than maybe catching the exception and trying again. I will point out that the task queue service is surprisingly resilient: out of tens/hundreds of thousands of task queue calls over the past 5 months that this application has performed, only 2 tasks (one in January 2024, one yesterday) have failed to enqueue. More importantly, my code is functioning as intended and I can mark this issue as Resolved or at least Muted.
Now honestly, this is a my bad sort of situation. If this was a real production app there should be something catching the exception. But since this is a toy application, I absolutely am fine tolerating the random and thankfully very rare failures in task queue.
I was working on some fun LeetCode type questions, and I came across a challenge to replicate the Vigenere cipher encryption and decryption in Python.
In short, the Vigenere cipher allows one to encrypt and decrypt a message if the user knows an alphabetic key. It’s notable for being easy to use; encryption and decryption are done by overlaying the key next to the message, then shifting the message letter by the letter number of the overlaid key. For more information, see the Wikipedia page discussing the Vigenere cipher .
The below functions are the “know-your-number-theory” / expected versions of how to encrypt/decrypt, where c is the encrypted message to decrypt, m is the unencrypted text to encrypt, and keyword is the secret encoding key.
def vigenere_decrypt_cipher(c: str, keyword: str) -> str:
keyword_repeated = (keyword * (len(c) // len(keyword))) + keyword[:len(c) % len(keyword)]
plaintext = ''
for i in range(len(c)):
if c[i].isalpha():
shift = ord(keyword_repeated[i].upper()) - ord('A')
if c[i].islower():
plaintext += chr((ord(c[i]) - ord('a') - shift) % 26 + ord('a'))
else:
plaintext += chr((ord(c[i]) - ord('A') - shift) % 26 + ord('A'))
else:
plaintext += c[i]
return plaintext
def vigenere_encrypt_message(m: str, keyword: str) -> str:
#filter to kick out spaces and punctuation
filtered_m = ""
for toon in m:
if toon.isalpha():
filtered_m = filtered_m + toon
else:
pass
#the rest to process the "real" stuff
m = filtered_m.upper()
keyword = keyword.upper()
encrypted_message = ''
keyword_repeated = (keyword * (len(m) // len(keyword))) + keyword[:len(m) % len(keyword)]
for i in range(len(m)):
char = m[i]
if char.isalpha():
shift = ord(keyword_repeated[i].upper()) - ord('A')
if char.islower():
encrypted_message += chr((ord(char) - ord('a') + shift) % 26 + ord('a'))
else:
encrypted_message += chr((ord(char) - ord('A') + shift) % 26 + ord('A'))
else:
encrypted_message += char
return encrypted_message.upper()
Honestly, while it was fun to implement, it’s not immediately obvious how Vigenere’s works from the code. So for fun I wrote the functions below, which sort of mimics how Vigenere messages would be coded/decoded by hand:
While these functions are much longer, I think they’re much more readable than the previous set of functions. These versions generate a matrix of 26×26 alphabets; the first row is a to z, the second row is shifted 1 to the right (b to z then a), the third row is shifted 2 to the right (c to z then ab), etc. Then we overlay the secret key and use it along with the message/encrypted message to encrypt/decrypt by finding the appropriate entry in our matrix. Admittedly the code is a little ugly and could be cleaned up, but I thought it would be fun to share.
Here’s some quick code samples for shifting a UTC datetime object (created_at is a datetime.utcnow()) to a different timezone. In this first example, we use timedelta to add/remove hours to find the current time at UTC-6:00.
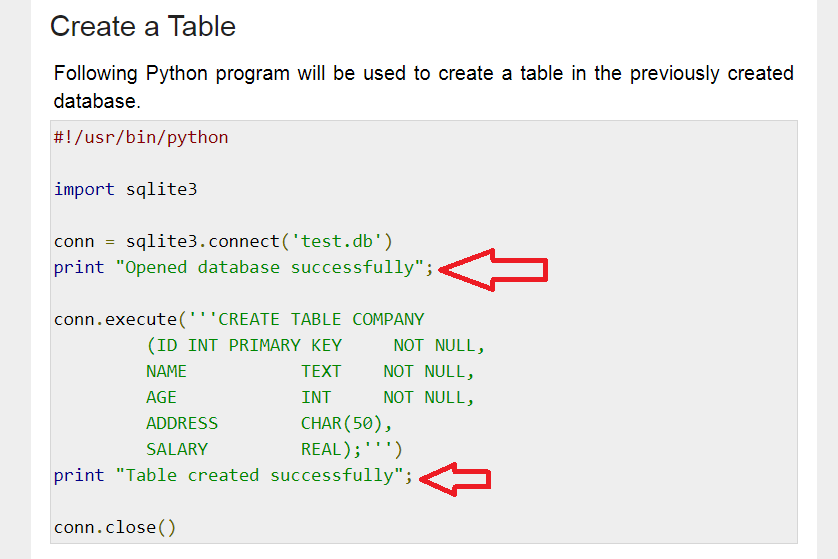
I’ve been experimenting with filtering and manipulating a large amount of data within a Google Cloud Function. I decided to use an in-memory SQLite database to help manage all the data, so I googled up some code samples. This page came up with some helpful Python code samples.
Unfortunately when I tried to run the sample code, Cloud Functions popped an error. The sample code uses Python 2-style print as a statement instead of as a function call – i.e. the print call is missing the parentheses needed to make it a correct function call. Here’s a sample screenshot:
I’ve placed red arrows next to the erroneous print statements. If you paste this code into Google Cloud Functions, it won’t work because print needs to be a function call, (with parentheses) instead of a statement (missing parentheses). Credit: https://www.tutorialspoint.com/sqlite/sqlite_python.htm
Below is a fixed version of the code in the linked page. You can paste it directly into the Google Cloud Functions editor and it’ll work: it sets up an in-memory database, creates a table, adds data, then queries data out of it.
import sqlite3
def hello_world(request):
"""Responds to any HTTP request.
Args:
request (flask.Request): HTTP request object.
Returns:
The response text or any set of values that can be turned into a
Response object using
`make_response <http://flask.pocoo.org/docs/1.0/api/#flask.Flask.make_response>`.
"""
conn = sqlite3.connect(":memory:")
conn.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print("Records created successfully");
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print("ID = ", row[0])
print("NAME = ", row[1])
print("ADDRESS = ", row[2])
print("SALARY = ", row[3], "\n")
conn.close()
request_json = request.get_json()
if request.args and 'message' in request.args:
return request.args.get('message')
elif request_json and 'message' in request_json:
return request_json['message']
else:
return f'Hello World!'
Use this code as a starting point to build your own cloud functions and work with data.
I’m pleasantly surprised at how fast SQLite runs within a cloud function – I was worried that the function would run out of memory quickly, but I’ve been manipulating thousands of rows comfortably within a 512MB RAM function.
After Google Reader was shut down, I moved to NewsBlur to follow my RSS feeds. The great thing about NewsBlur is that you can add RSS feeds to a folder and Newsblur will merge all the stories under that folder into a single RSS feed.
Under NewsBlur, you’ll want to pull the folder RSS feed from the settings option:
The following Python code can pull the feed and iterate through it to find article information. At the bottom of this code example, each child represents a possible article, and sub_child represents a property on the article: the URL, the title, etc. I use a variant of this code to help identify important news stories.
import requests
import xml.etree.ElementTree as ET
import logging
import datetime, pytz
import json
import urllib.parse
#tears through the newsblur folder xml searching for <entry> items
def parse_newsblur_xml():
r = requests.get('NEWSBLUR_FOLDER_RSS')
if r.status_code != 200:
print("ERROR: Unable to retrieve address ")
return "error"
xml = r.text
xml_root = ET.fromstring(xml)
#we search for <entry> tags because each entry tag stores a single article from a RSS feed
for child in xml_root:
if not child.tag.endswith("entry"):
continue
#if we are down here, the tag is an entry tag and we need to parse out info
#Grind through the children of the <entry> tag
for sub_child in child:
if sub_child.tag.endswith("category"): #article categories
#call sub_child.get('term') to get categories of this article
elif sub_child.tag.endswith("title"): #article title
#call sub_child.text to get article title
elif sub_child.tag.endswith("summary"): #article summary
#call sub_child.text to get article summary
elif sub_child.tag.endswith("link"):
#call sub_child.get('href') to get article URL
However, it seems that the API insists on having the correct request content type set; i.e. you must set Content-Type: application/json for the IBM Watson servers to notice there is a data body in the POST request. I fixed it by using the json parameter – the requests library for Python automatically inserts the application/json content type when this parameter is used. If you use a different language, you’ll need to set the proper content type in the language’s preferred manner.
I saw this fun tool on YC News called pysnooper: https://news.ycombinator.com/item?id=19717786 . I’ve been trying it out all day on various Python applications, and it’s actually making debugging fun and a whole lot easier!
I use PhantomJSCloud to take screenshots of web apps. While writing new code, I noticed this error coming back from the server:
{
"name":"HttpStatusCodeException",
"statusCode":400,
"message":"Error extracting userRequest. innerException: JSON5: invalid character 'u' at 1:1",
"stack":[
"no stack unless env is DEV or TEST, or logLevel is DEBUG or TRACE"
]
}
The problem came because the request wasn’t JSON-encoding the object; the fix looks like this (using the requests library):