Now I am a numbers and data person. I love using data, building metrics, and so on to figure out the right answer. But when it comes to SEO, I have a hard time believing a lot of the “studies” that come out. I put that in quotes because many of these studies aren’t worth the pixels used to paint the text.
There are so many variables when it comes to SEO, so many moving targets, that it’s almost impossible to allocate credit to what worked and what didn’t work. This is exactly the reason why I advocate working on the brand. Instead of burning time trying to squeeze another half a percent more out of SEO, instead work on burnishing your brand.
Which brings me to this Search Engine Land article commenting on local search, with this gem:
For instance, while past stats suggested 76% of people check out a brand’s online presence before visiting in person, that story is shifting… Which brands stick.
Meanwhile, the basics still matter. Great customer service, strong community ties, memorable in-person experiences—these remain the foundation of building a local audience. What’s new is that these moments now shape what AI sees, what content surfaces in feeds, and what earns trust at scale.
Yes, absolutely. As we move into an increasingly AI driven world, the easiest thing to quantify is not the quality of blog writing, or if the blog writing is actually true. The easiest thing for AIs to do is to quantify which brands are the most trusted, and then to leverage those brands as the base to generate their text out of.
Which takes me to this Reddit post covering a Ahrefs study: Websites With More Organic Search Traffic Get Mentioned More In AI Search. There should be an obvious tag all over that headline because it makes intuitive sense: Websites with better/more-respected branding are considered more authoritative, and therefore they should get mentioned more.
So bottom line: as we move towards the AI-ification of marketing, the winner takes it all. Take good care of your brand. Keep it squeaky clean and you will see dividends.
From the “my blog is actually my code backup store” department, this is a simple function I use on Google Cloud to accept a base64-encoded zip file, then unzip it all to a Google Cloud Storage bucket.
import functions_framework
import base64
from google.cloud import storage
import zipfile
import os
import datetime, pytz
@functions_framework.http
def hello_http(request):
#pull out the base64 encoded data and decode it.
request_bytes = base64.b64decode(request.get_data())
print(len(request_bytes))
print(request.data)
print(request.content_length)
print(request.method)
print(request.method)
print("request load: " + str(len(request_bytes)))
#generate working directory prefix name
datetime_string = datetime.datetime.now(pytz.timezone("US/Central")).isoformat()
print("Current Chicago Date-Time: %s" % (datetime_string))
directory_prefix = datetime_string[:19].replace(":", "-")
#dump to GCS
gcs_client = storage.Client()
gcs_bucket = gcs_client.get_bucket("bucket name goes here")
file_blob = storage.Blob("/zipped/" + directory_prefix + ".zip", gcs_bucket)
file_blob.upload_from_string(request_bytes, content_type="application/zip", client=gcs_client)
#dump to temporary directory within functions
with open("/tmp/" + directory_prefix + ".zip", "wb") as file:
file.write(request_bytes)
file.flush()
file.close()
#extract zipfile
zip_file = zipfile.ZipFile("/tmp/" + directory_prefix + ".zip")
zip_file.extractall("/tmp/local/unzip/" + directory_prefix + "/")
#go through extracted files
for file_name in os.listdir("/tmp/local/unzip/" + directory_prefix + "/"):
print(str(file_name))
file_blob = storage.Blob("/open/" + directory_prefix + "/" + file_name + "", gcs_bucket)
file_blob.upload_from_filename("/tmp/local/unzip/" + directory_prefix + "/" + file_name + "", client=gcs_client)
print("end")
return str(len(request_bytes))
You may want to alter the date reference (the US/Central note) but otherwise it’s a small and efficient tool for moving data where I can easily reference it later by date.
A bit too late for a Christmas wish, but this was sticking on my mind.
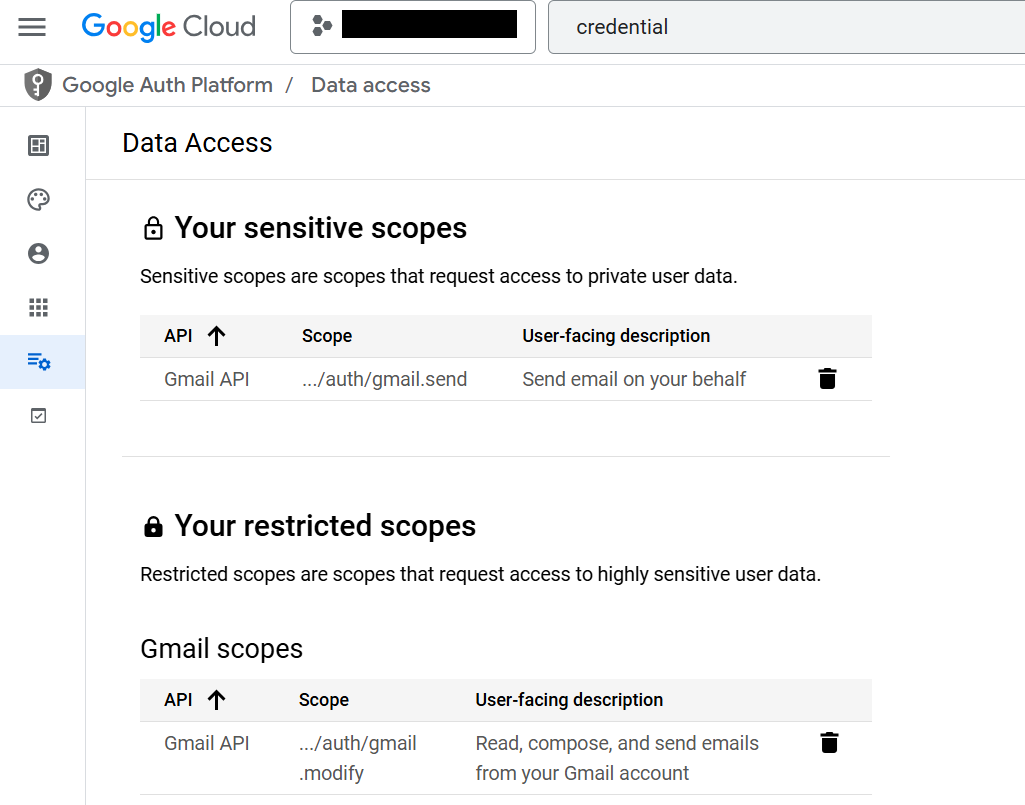
If you’ve worked with Google APIs, you’re probably familiar with the idea of sensitive/restricted scopes. Sensitive and restricted scopes are scopes that Google believes access private data, so apps using these scopes need review. Sensitive scopes require review by a Google employee. Restricted scopes need a full on security audit, which can cost tens of thousands of dollars.
One thing I respect about Gmail (amongst the many, many things I respect) is that Gmail is pretty well scoped: to send an email (not to interact with drafts/sent/any inbox), an app can use the gmail.send scope. To do anything else with Gmail pretty much requires a restricted scope:
What I would really like to see is an auth scope that is neither restricted or sensitive, but only allows a Gmail message to be sent to the owner of the Gmail account. In other words, for the Gmail account to send an email to itself. It would be a good way for apps to send their administrator periodic messages without having to worry about spam filters, or for an user to essentially cosign for a website’s need to email them.
While I’m on my wish list for auth scopes, I wish youtube.readonly wasn’t a sensitive scope. I think it should either be non-sensitive, or broken down into finer grained scopes. For example, I’d love to see a scope that permits read-only access to an user’s subscribed YouTube channels
This helps to underline that your customers are not only looking at your website, but they’re also looking up reviews of your products on other venues. Now I don’t agree with this post 100%: there are two things I would add. Number one is to post high quality images and videos of your product – if you’re missing those, of course customers are going to try to find them on other venues.
The second item is that not just Gen Z does this: I’m a millennial and I frequently do the same – look up videos and reviews on YouTube, Facebook, etc.
This post is a great example of why it’s important for you to curate your presence across all social media channels, and even why linking sales to a particular funnel is hard – if a Google ad had brought the customer to this product, would you credit the Google ad, or the TikTok/YouTube/Instagram/Facebook review of it for making the sale?
And here’s your daily reminder that local search gets weird, fast. If I had this client, what I would have suggested is to build a separate site for each dentist, naming each site some version of (dentist/teeth/tooth/some-other-synonym-or-related-word-to-teeth)(city-name) . com. And someone did make a similar comment to that in the comments of that post. Local SEO can be a surprisingly fun place to specialize in because the “normal” SEO tips are often inverted and Google Search seems to take into account more local-specific details rather than focusing on the technical hints that pages offer.
There was a terrific post from Vercel’s blog How Google handles JavaScript throughout the indexing process. The short version of this post is yes, the Google indexer/spider can read content loaded through Javascript. That should come as no surprise to most professional SEO-ers out there, but it’s always worth a reminder. I did want to highlight one or possibly two important items in the recommendations section.
Critical SEO elements: Use server-side rendering or static generation for critical SEO tags and important content to ensure they’re present in the initial HTML response.
Content updates: For content that needs to be quickly re-indexed, ensure changes are reflected in the server-rendered HTML, not just in client-side JavaScript. Consider strategies… to balance content freshness with SEO and performance.
Yes, the Google spider can read Javascript. At the same time, there are tradeoffs to be considered, such as if scripting is slow loading the content, then the spider “sees” your page as being slow and possibly annoying to the user.
My thoughts are: if you’re scroll-loading/infinite scrolling content (i.e. the user scrolls down the page and more posts/images/whatever keep appearing) don’t assume that the Google spider is going to keep scrolling down forever. Your site should have an alternative way to link to those posts/images, such as through a tags or categories section, or through a calendar widget like the one on learngoogle.com’s home page. Have a sitemap so Google’s spider isn’t reliant on having to use Javascript to see all of your pages. Make sure that any scripts loading content run fast, and are not heavily changing the layout of the page.
I saw this blog post on Hacker News, and it was so notable that I was thinking about it for the past week. I disagree on its major points for technical reasons, but I agree in that you should SEO with the thought that it’s true.
But first, I want to make a distinction here. When Google hits a website and looks at its content for possible inclusion into its search index, we call that “spidering”. That’s not a word plucked out of nowhere – we call web crawlers searching for content “spiders” and there’s a long technical history behind that.
In my experience, Google spiders basically everything – even places maybe you wish Google didn’t find such as admin pages. And frankly this makes sense – spidering your web site doesn’t only give information about your website, but it also gets Google information about how it should rank other web pages. For example, Google gets information about the sites you link out to, which contributes to PageRank calculations of how other web pages should be ranked. A second example is that by spidering all the web pages, Google can find scraped/duplicate content and possibly consider the offending domain (not necessarily your domain!) for SEO penalties.
So if there is an incentive to spider everything, you can see where I disagree with the blog post:
I think it’s very unreasonable to say “Google is no longer trying to index the entire web.” There are huge incentives for Google to spider and at least know about the entire web, even if they don’t actually show the web pages it knows about in its search.
First off, most people don’t go past the first page of search results anymore. For a majority of searches, the answers from Google’s AI summary/the first few results (regardless of whether they’re ads or not) will show up with the answer. 60% of searches don’t even result in a click to an outside web page. So even if Google knows about additional web sites that might match the search, is it worth the computing power to resolve the rankings much below the 20th search result slot or even farther?
There’s a human analog here: people do not want to hear additional details. They want you to get to the point as fast as possible. Here’s a Miss Manners article on “Is there any polite way to encourage someone who is recounting an anecdote to you to come to the point a little faster?” I find it reasonable to assume Google search is simply getting to the point and not showing sites that – even though they have relevant information – that information is already available on the other competing web pages that are higher ranked.
So in short, I disagree with this blog article on a technical basis. I don’t think it’s quite so easy to to say because a web page is not showing up in a Google search, that automatically equals Google didn’t see it or care about it or that it’s not in the Google index.
On the other hand, I think the blog’s deeper point is true. We’ve reached the point in the Internet where there are lots of good competing information sources. If you want to launch a competitor, you need to have a value proposition and a niche: a place that you can get started. For example, suppose you have a Pizza Hut, Papa Johns, (insert your favorite pizza place here) in your town. Your townspeople are generally happy with the pizza available, and there’s no obvious need for another pizza place. If you want to launch a new pizza restaurant, you can’t just say, “We sell pizza.” You have to have a value proposition different than Pizza Hut/Papa Johns/etc: maybe the pizza at your restaurant is meatier/cheesier/better crust/whatever better than the competitors.
The same goes for content: if you want to launch a new website, you need to have a value proposition different than what your competitors are offering if you want a space in Google search rankings. You need to develop a following as an expert in some niche in order to compete with better, more well funded competitors especially if you’re a smaller blog.
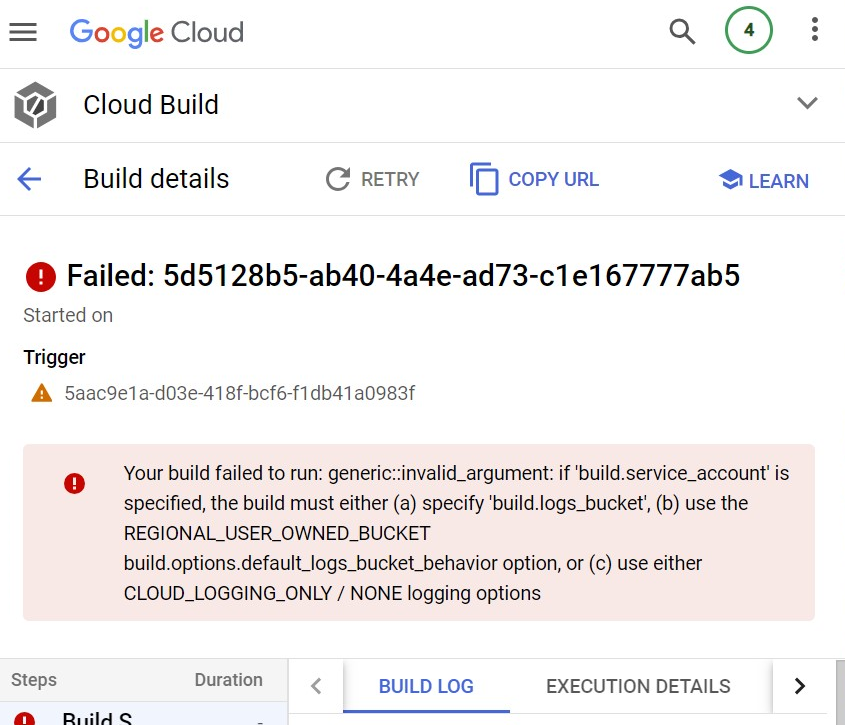
I was updating some Cloud Build triggers and I’m not sure what changed – I think that the service account field when configuring a new build trigger is now mandatory because I don’t recall ever having to set that field before.
Also, this is the first time I’ve ever seen the below error:
Your build failed to run: generic::invalid_argument: if ‘build.service_account’ is specified, the build must either (a) specify ‘build.logs_bucket’, (b) use the REGIONAL_USER_OWNED_BUCKET build.options.default_logs_bucket_behavior option, or (c) use either CLOUD_LOGGING_ONLY / NONE logging options
Google Cloud Build
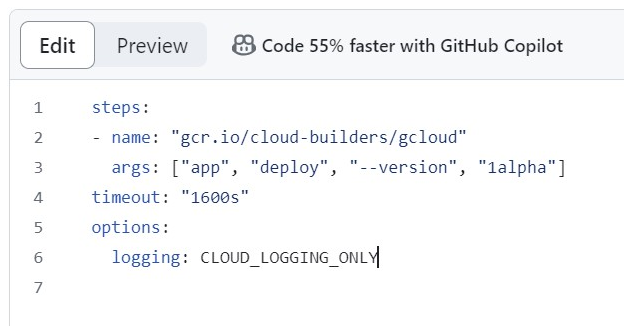
And the fix is obviously just to configure cloud logging in the cloudbuild.yaml file in my repository:
I have a domain that I used for email almost 20 years ago. I don’t use it for (important!) email anymore, nor really for any other purpose, but I do occasionally check the email account attached to the domain every week or so in case something important gets sent through. Most of the time it’s nothing more than a few hundred messages from various listservs I’ve been on for a long time.
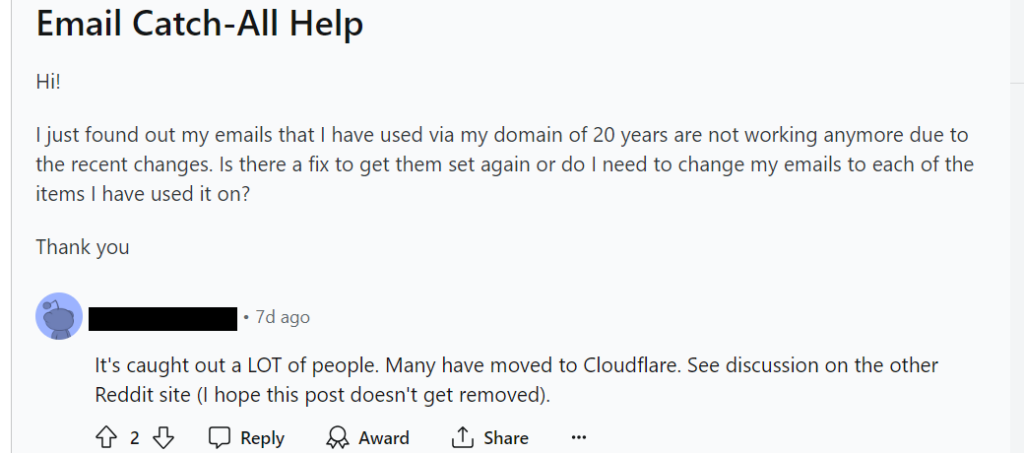
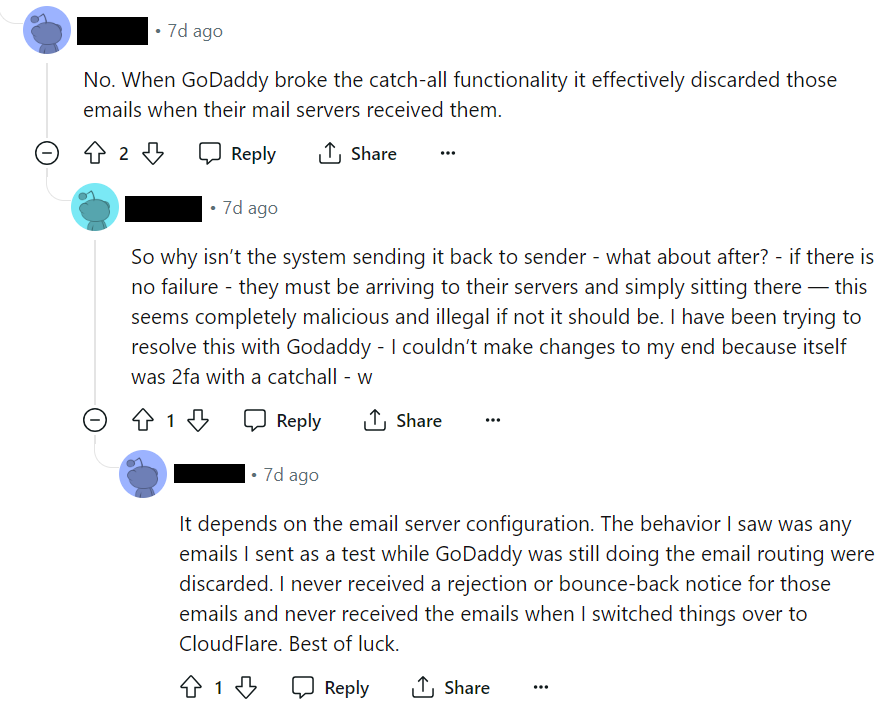
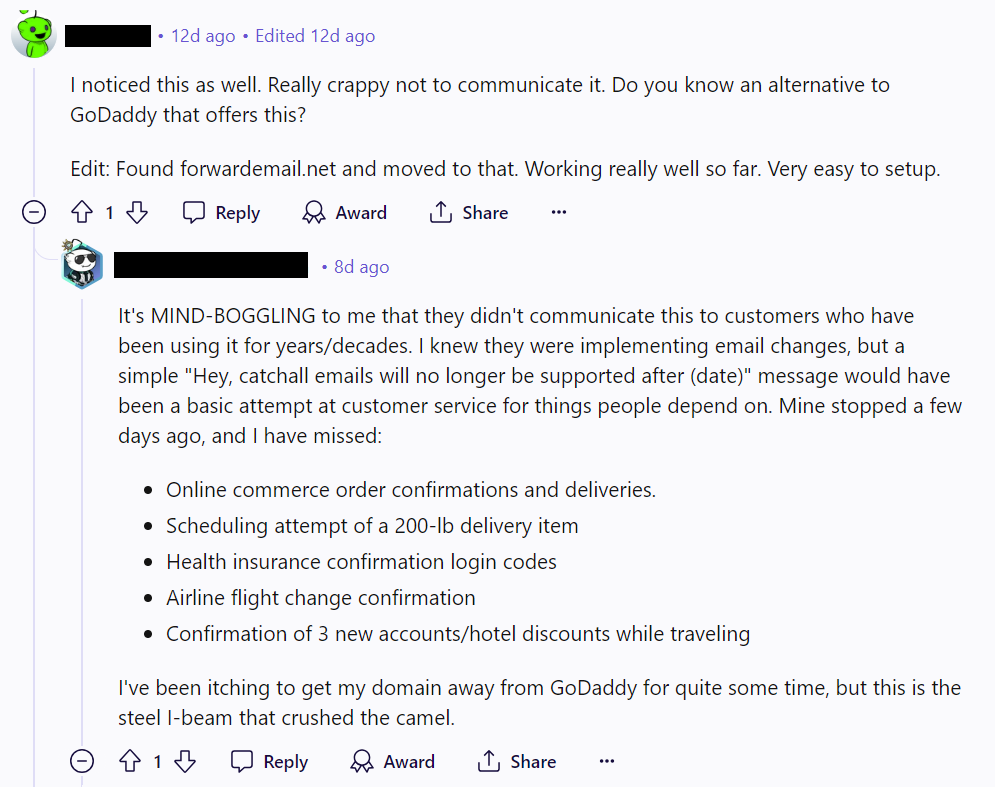
So you can imagine my surprise when I logged onto the email account and saw zero new messages – very unusual since those listservs have a lot of daily traffic. After some Googling, I found that GoDaddy’s catch all email forwarders apparently no longer work. Here’s an example post from Reddit on the situation: https://www.reddit.com/r/godaddy/comments/1d94771/email_catchall_help/ .
What really annoys me is that the email forwarding is silently broken – there’s no rejection email or anything. I tried to send some emails to my email-forwarded domain and none of them went through, nor were they rejected. Again, here’s a Reddit post documenting this: https://www.reddit.com/r/DontGoDaddy/comments/1d1pvim/comment/l7d2ua5/ .
I’m pretty disappointed in how email forwarding from GoDaddy was shut down. Free email forwarding has been basically free with domain registration for a long time with any decent registrar.
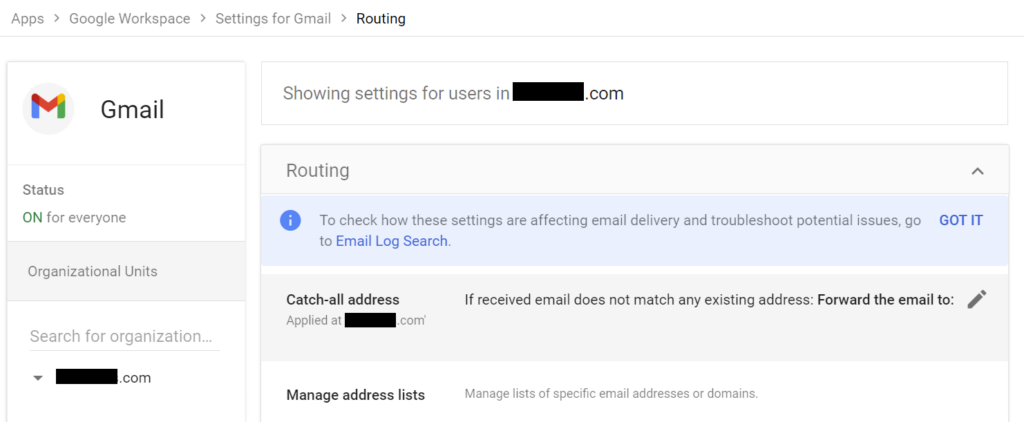
Anyway to fix this, I’ve been rerouting a bunch of domains to map to my Google Apps account as alias domains, then mapping the catchall address in Gmail Routing to map to my main account as in the picture below.
Once again, Google to the rescue, but I am seriously annoyed at having to work around GoDaddy issues. The fact that they gave zero warning of this change is concerning to say the least.
For today, I wanted to record a quick observation I had while Googling. It’s also a reminder that choosing the correct search terms can drastically change what Google returns to you.
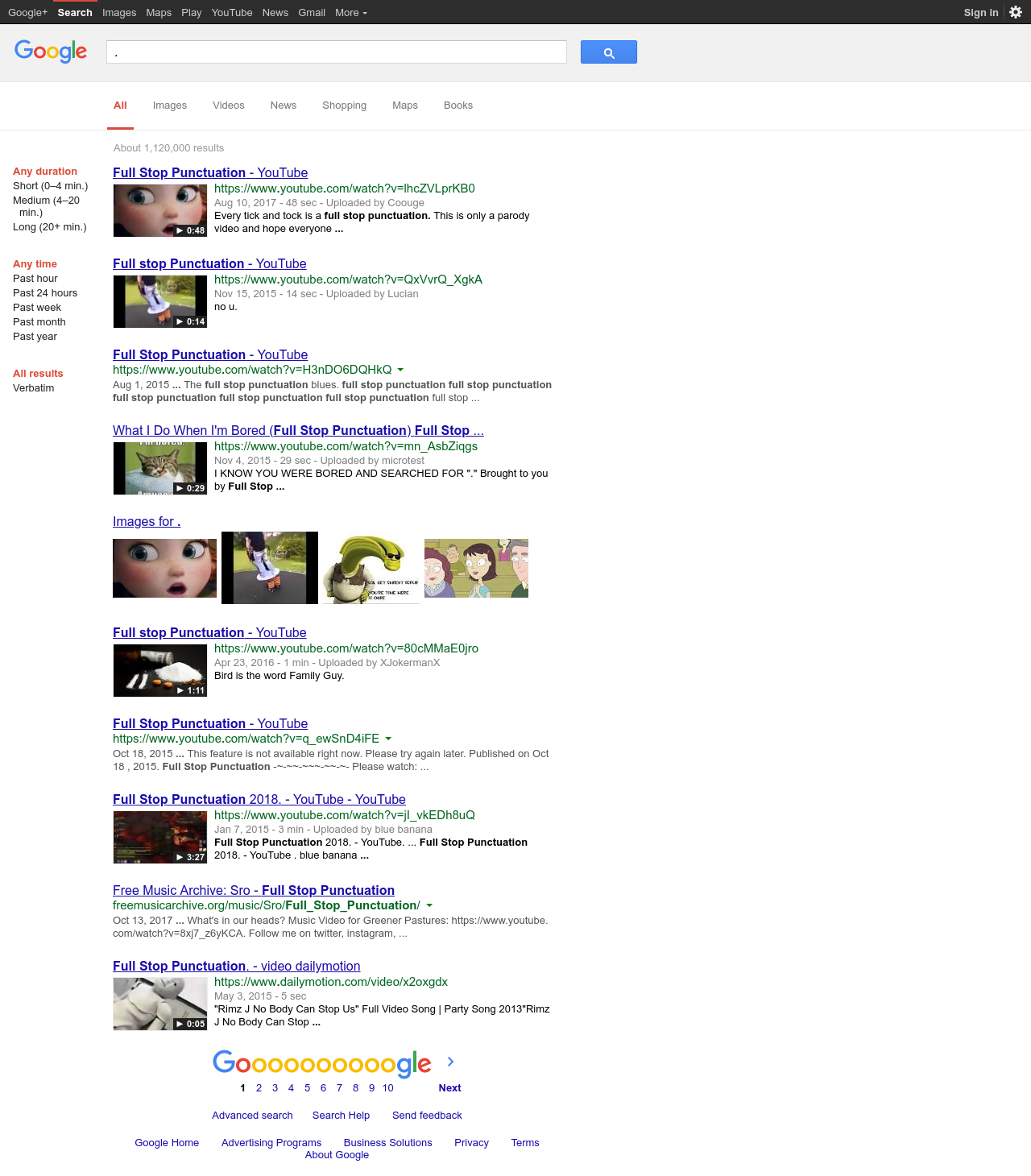
If I Google for the period symbol (.), I get back results for the phrase “full stop punctuation.” I know this because the words “full stop punctuation” are bolded in the returned Google page. Here’s a screenshot in case that changes:
Note that the links aren’t terribly interesting – I don’t see any links to punctuation or style guides, just pages with the words “full stop punctuation.”
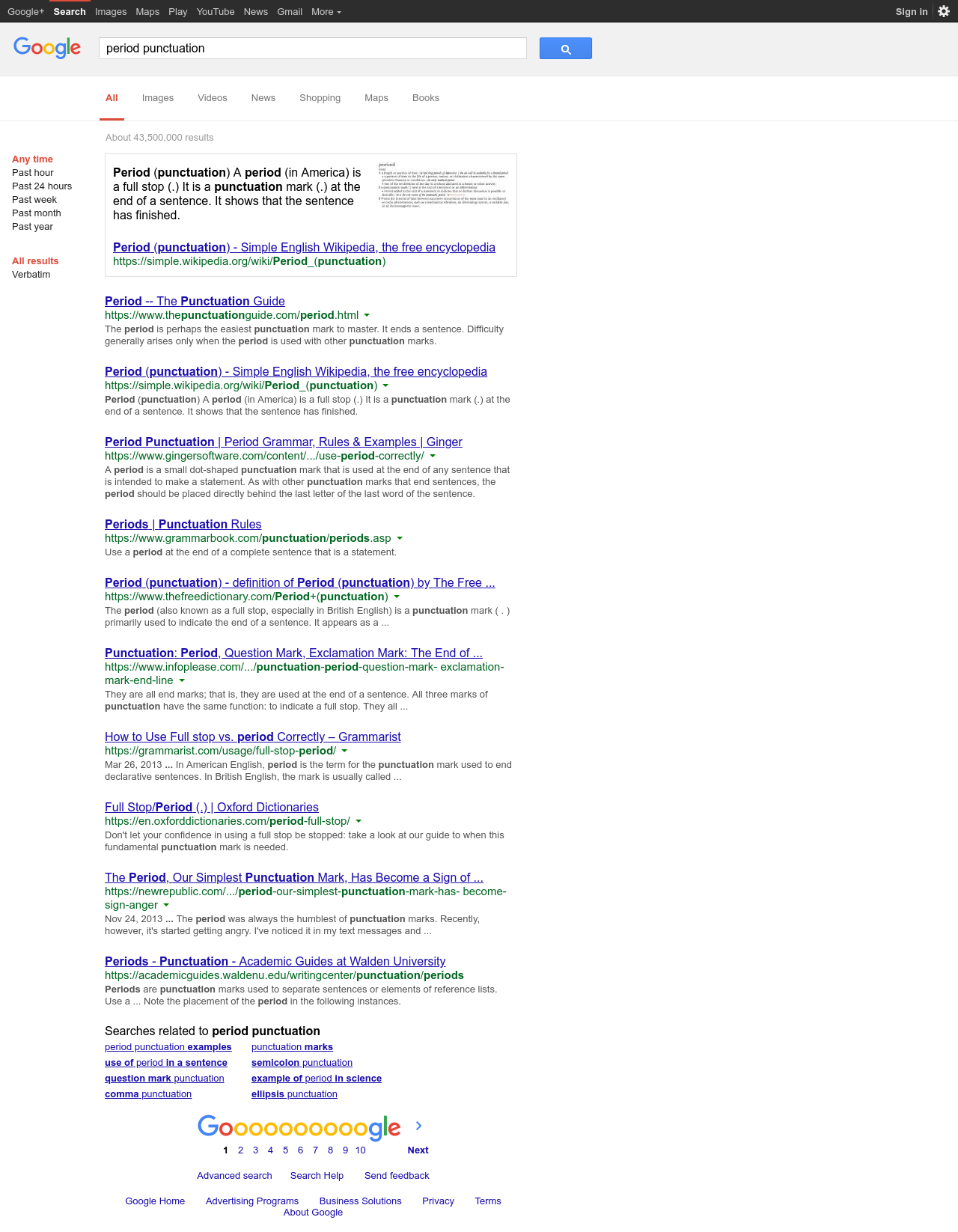
Now interestingly, if I search for the words “period punctuation”, I get back a small context box explaining to me what a period is used for in writing, as well as a list of punctuation and writing guides:
The results for a Google search for “period punctuation.”
As you can see, a minor change in search terms dramatically changes what you get, even if both terms mean largely the same thing.
I know a lot of enterprise cloud customers have been watching the recent incident with Google Cloud (GCP) and UniSuper. For those of you who haven’t seen it: UniSuper is an Australian pension fund firm which had their services hosted on Google Cloud. For some weird reason, their private cloud project was completely deleted. Google’s postmortem of the project is here: https://cloud.google.com/blog/products/infrastructure/details-of-google-cloud-gcve-incident . Fascinating reading – in particular what surprises me is that GCP takes full blame for the incident. There must be some very interesting calls occurring with Google and their other enterprise customers.
There’s some fascinating morsels to consider in Google’s postmortem of the incident. Consider this passage:
Data backups that were stored in Google Cloud Storage in the same region were not impacted by the deletion, and, along with third party backup software, were instrumental in aiding the rapid restoration.
Fortunately for UniSuper, the data in Google Cloud Storage didn’t seem to be affected and they were able to restore from there. But it looks like UniSuper also had a another set of data stored with another cloud. The following is from UniSuper’s explanation of the event at: https://www.unisuper.com.au/contact-us/outage-update .
UniSuper had backups in place with an additional service provider. These backups have minimised data loss, and significantly improved the ability of UniSuper and Google Cloud to complete the restoration.
Having a full set of backups with another service provider has to be terrifically expensive. I’d be curious to see a discussion of who the additional service provider is and a discussion of the costs. I also wonder if the backup cloud is live-synced with the GCP servers or if there’s a daily/weekly sync of the data to help reduce costs.
The GCP statement seems to say that the restoration was completed with just the data from Google Cloud Storage, while the UniSuper statement is a bit more ambiguous – you could read the statement as either (1) the offsite data was used to complete the restoration or (2) the offsite data was useful but not vital to the restoration effort.
I did a quick dive to figure out where these requirements are coming from, and from the best that I could tell, these requirements come from the APRA’s Prudential Standard CPS 230 – Operational Risk Management document. Here’s some interesting lines from there:
An APRA-regulated entity must, to the extent practicable, prevent disruption to critical operations, adapt processes and systems to continue to operate within tolerance levels in the event of a disruption and return to normal operations promptly once a disruption is over.
An APRA-regulated entity must not rely on a service provider unless it can ensure that in doing so it can continue to meet its prudential obligations in full and effectively manage the associated risks.
Australian Prudential Regulation Authority (APRA) – Prudential Standard CPS 230 Operational Risk Management
I think the “rely on a service provider” is the most interesting text here. I wonder if – by keeping a set of data on another cloud provider – UniSuper can justify to the APRA that it’s not relying on any single cloud provider but instead has diversified its risks.
I couldn’t find any discussion about the maximum amount of downtime allowed, so I’m not sure where the “4 week” tolerance from the HN comment came from. Most likely that is from industry norms. But I did find some text about tolerance levels of disruptive events:
38. For each critical operation, an APRA-regulated entity must establish tolerance levels for: (a) the maximum period of time the entity would tolerate a disruption to the operation
Australian Prudential Regulation Authority (APRA) – Prudential Standard CPS 230 Operational Risk Management
It’s definitely interesting to see how requirements for enterprise cloud customers grow from their regulators and other interested parties. There’s often some justification underlying every decision (such as duplicating data across clouds) no matter how strange it seems at first.
APRA History On The Cloud
While digging into this subject, I found it quite interesting to trace how the APRA changed its tune about cloud computing over the years. As recently as 2010, the APRA felt the need to, “emphasise the need for proper risk and governance processes for all outsourcing and offshoring arrangements.” Here’s an interesting excerpt from their 2010 letter sent to all APRA-overseen financial companies:
Although the use of cloud computing is not yet widespread in the financial services industry, several APRA-regulated institutions are considering, or already utilising, selected cloud computing based services. Examples of such services include mail (and instant messaging), scheduling (calendar), collaboration (including workflow) applications and CRM solutions. While these applications may seem innocuous, the reality is that they may form an integral part of an institution’s core business processes, including both approval and decision-making, and can be material and critical to the ongoing operations of the institution. APRA has noted that its regulated institutions do not always recognise the significance of cloud computing initiatives and fail to acknowledge the outsourcing and/or offshoring elements in them. As a consequence, the initiatives are not being subjected to the usual rigour of existing outsourcing and risk management frameworks, and the board and senior management are not fully informed and engaged.
While the letter itself seems rather innocuous, it seems to have had a bit of a chilling effect on Australian banks: this article comments that, “no customers in the finance or government sector were willing to speak on the record for fear of drawing undue attention by regulators“.
An APRA document published on July 6, 2015 seems to be even more critical of the cloud. Here’s a very interesting quote from page 6:
In light of weaknesses in arrangements observed by APRA, it is not readily evident that risk management and mitigation techniques for public cloud arrangements have reached a level of maturity commensurate with usages having an extreme impact if disrupted. Extreme impacts can be financial and/or reputational, potentially threatening the ongoing ability of the APRA-regulated entity to meet its obligations.
Then just three years later, the APRA seems to be much more friendly to cloud computing. A ComputerWorld article entitled “Banking regulator warms to cloud computing” published on September 24, 2018 quotes the APRA chair as acknowledging, “advancements in the safety and security in using the cloud, as well as the increased appetite for doing so, especially among new and aspiring entities that want to take a cloud-first approach to data storage and management.”
It’s curious to see the evolution of how organizations consider the cloud. I think UniSuper/GCP’s quick restoration of their cloud projects will result in a much more friendly environment toward the cloud.