I always love pointing out fun errors – where I define “fun error” as an error that is intermittent/happens rarely in the context of regular operation in the application. Those errors are always the most fun to fix.
Today I was poking through some of my toy applications running on Google Cloud when I saw this:
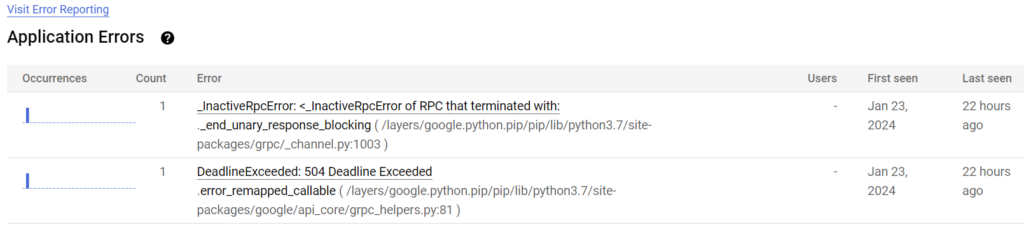
And the text only:
_InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
._end_unary_response_blocking ( /layers/google.python.pip/pip/lib/python3.7/site-packages/grpc/_channel.py:1003 ) - Jan 23, 2024 22 hours ago -
DeadlineExceeded: 504 Deadline Exceeded
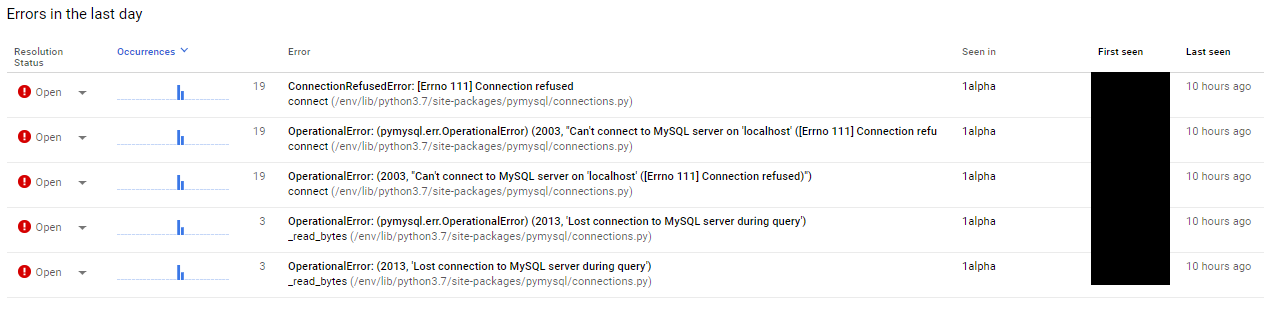
.error_remapped_callable ( /layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/grpc_helpers.py:81 ) - Jan 23, 2024 22 hours agoHmm – so an error occurred 22 hours ago, that last reoccurred almost 4 months ago (Jan 23, 2024). Doesn’t sound very important. But just for the laughs, let’s dig in.
Of the two errors, I know that the first one (InactiveRPCError) is most likely due to a connection being unable to complete. Not a giant problem, happens all the time in the cloud – servers get rebooted, VMs get shuffled off to another machine, etc. Not a serious problem. The deadline exceeded one concerns me though because I know this application connects to a bunch of different APIs and does a ton of time consuming operations, and I want to make sure that everything is back to normal.
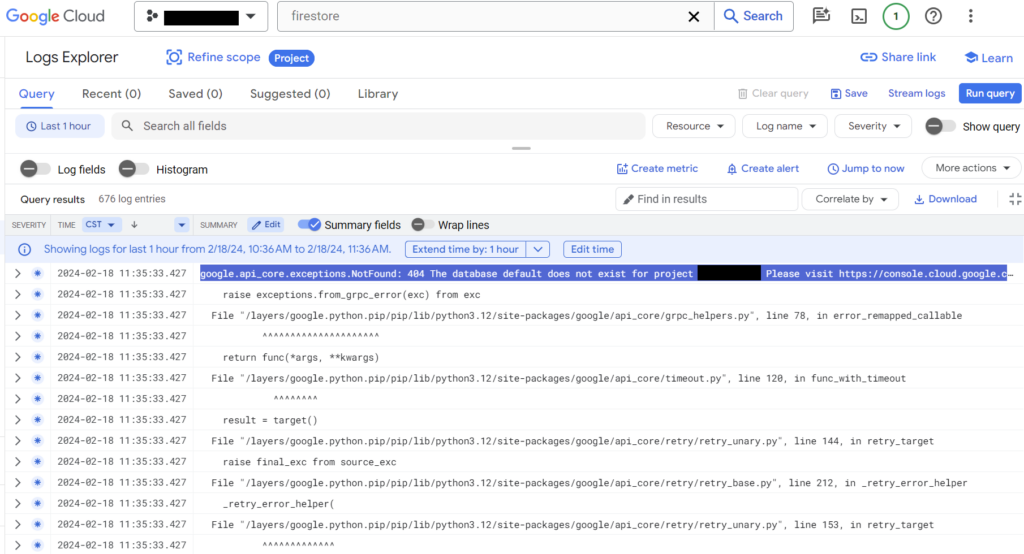
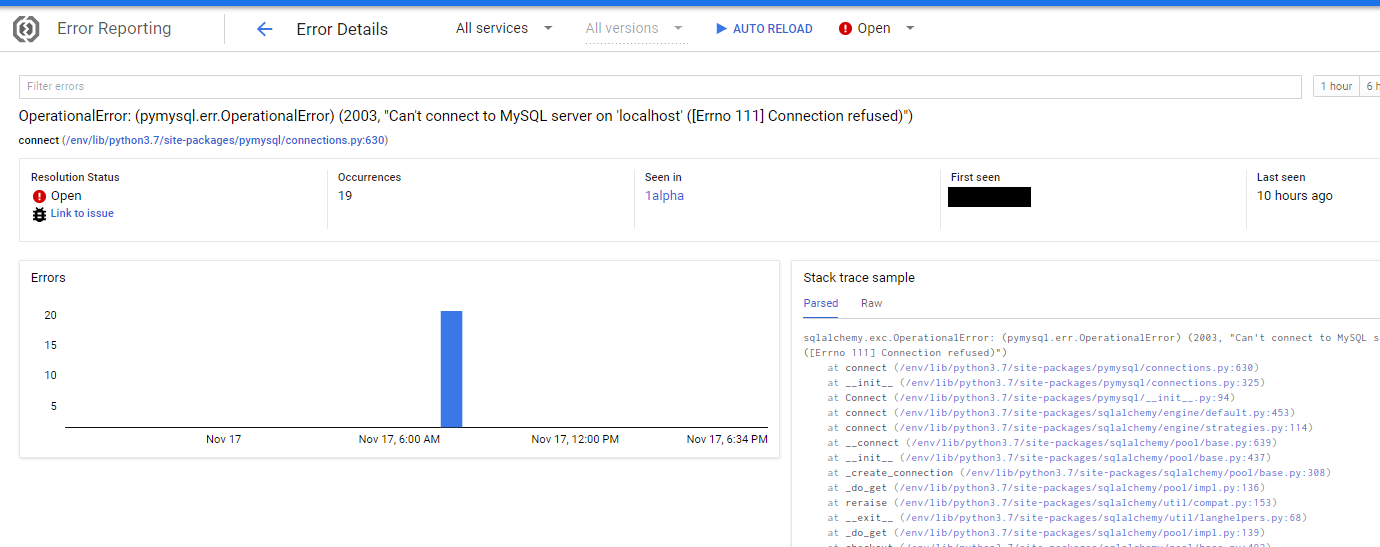
So here’s the view of the error page:
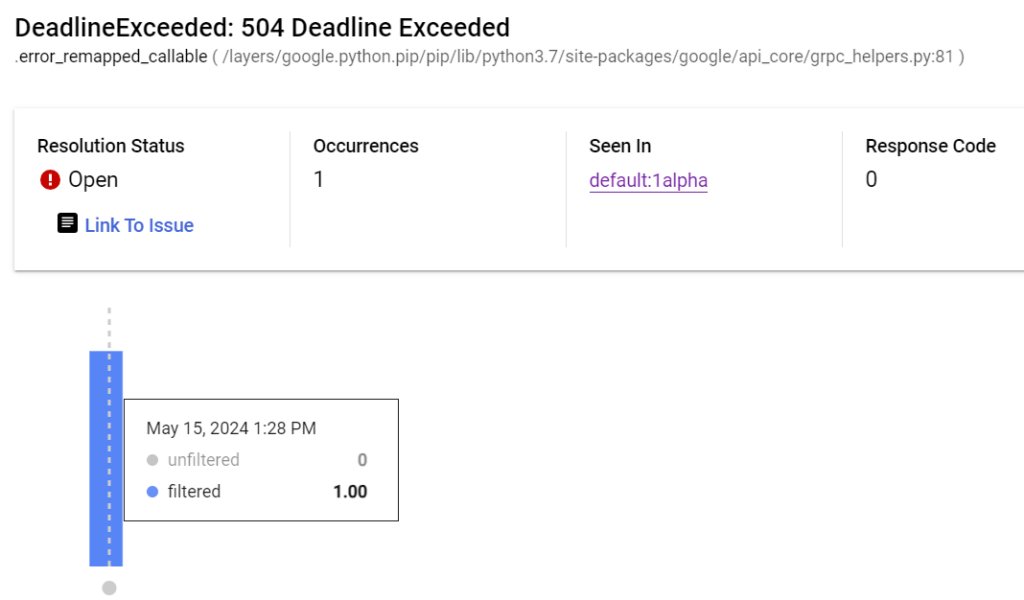
So I know that the error is somewhere communicating with Google services since the error pops up in the google api core library. Let’s hop on over to logging and find the stack trace – I’ve redacted a line that doesn’t mean anything to the purpose of this post:
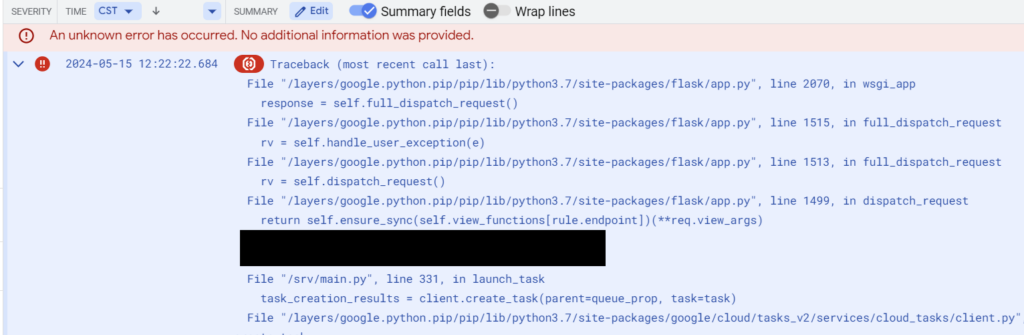
Traceback (most recent call last):
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 2070, in wsgi_app
response = self.full_dispatch_request()
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1515, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1513, in full_dispatch_request
rv = self.dispatch_request()
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/flask/app.py", line 1499, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args)
[REDACTED]
File "/srv/main.py", line 331, in launch_task
task_creation_results = client.create_task(parent=queue_prop, task=task)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/cloud/tasks_v2/services/cloud_tasks/client.py", line 2203, in create_task
metadata=metadata,
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/gapic_v1/method.py", line 131, in __call__
return wrapped_func(*args, **kwargs)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/timeout.py", line 120, in func_with_timeout
return func(*args, **kwargs)
File "/layers/google.python.pip/pip/lib/python3.7/site-packages/google/api_core/grpc_helpers.py", line 81, in error_remapped_callable
raise exceptions.from_grpc_error(exc) from exc
google.api_core.exceptions.DeadlineExceeded: 504 Deadline Exceeded
If you missed the culprit in the above text, let me help you out: the call to the Google Task Queue service on line 331 of my application ended up exceeding Google’s deadline, and threw up the exception from Google’s end. Perhaps there was a transient infrastructure issue, perhaps task queue was under maintenance, perhaps it was just bad luck.
File "/srv/main.py", line 331, in launch_task
task_creation_results = client.create_task(parent=queue_prop, task=task)There’s really nothing to be done here, other than maybe catching the exception and trying again. I will point out that the task queue service is surprisingly resilient: out of tens/hundreds of thousands of task queue calls over the past 5 months that this application has performed, only 2 tasks (one in January 2024, one yesterday) have failed to enqueue. More importantly, my code is functioning as intended and I can mark this issue as Resolved or at least Muted.
Now honestly, this is a my bad sort of situation. If this was a real production app there should be something catching the exception. But since this is a toy application, I absolutely am fine tolerating the random and thankfully very rare failures in task queue.