I’ve remarked before about how I love Newsblur as a replacement for Google Reader. But Newsblur can also watch for new YouTube videos via YouTube RSS feeds!
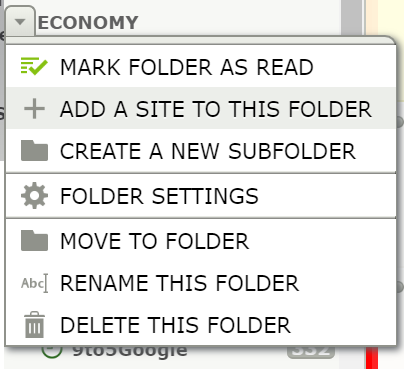
RSS support is not always clearly advertised on YouTube, but it’s simple to access. In NewsBlur, right click a folder and select Add A Site To This Folder:
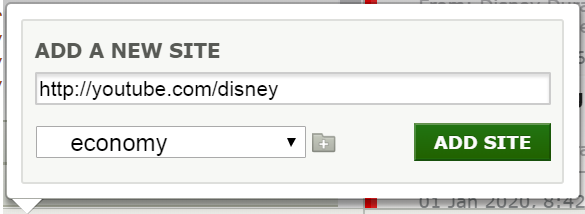
Then just insert the YouTube channel URL, and NewsBlur should load the newest YouTube videos!
This is a quick and easy way for me to monitor a lot of YouTube channels at once.
After Google Reader was shut down, I moved to NewsBlur to follow my RSS feeds. The great thing about NewsBlur is that you can add RSS feeds to a folder and Newsblur will merge all the stories under that folder into a single RSS feed.
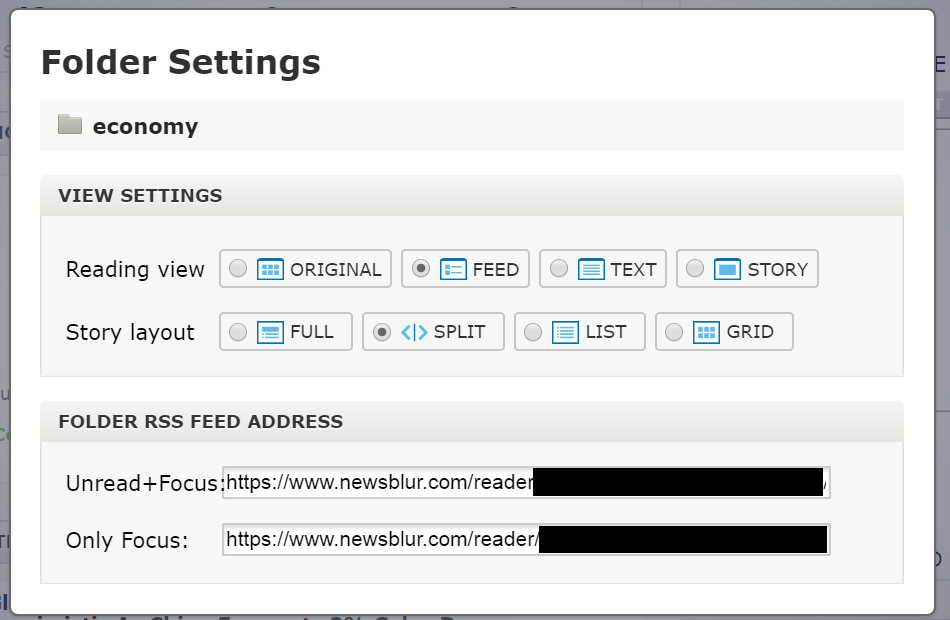
Under NewsBlur, you’ll want to pull the folder RSS feed from the settings option:
The following Python code can pull the feed and iterate through it to find article information. At the bottom of this code example, each child represents a possible article, and sub_child represents a property on the article: the URL, the title, etc. I use a variant of this code to help identify important news stories.
import requests
import xml.etree.ElementTree as ET
import logging
import datetime, pytz
import json
import urllib.parse
#tears through the newsblur folder xml searching for <entry> items
def parse_newsblur_xml():
r = requests.get('NEWSBLUR_FOLDER_RSS')
if r.status_code != 200:
print("ERROR: Unable to retrieve address ")
return "error"
xml = r.text
xml_root = ET.fromstring(xml)
#we search for <entry> tags because each entry tag stores a single article from a RSS feed
for child in xml_root:
if not child.tag.endswith("entry"):
continue
#if we are down here, the tag is an entry tag and we need to parse out info
#Grind through the children of the <entry> tag
for sub_child in child:
if sub_child.tag.endswith("category"): #article categories
#call sub_child.get('term') to get categories of this article
elif sub_child.tag.endswith("title"): #article title
#call sub_child.text to get article title
elif sub_child.tag.endswith("summary"): #article summary
#call sub_child.text to get article summary
elif sub_child.tag.endswith("link"):
#call sub_child.get('href') to get article URL